# Importación de bibliotecas básicas
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Configuración para visualizaciones
%matplotlib inline
sns.set_style("whitegrid")
plt.rcParams['figure.figsize'] = (10, 6)Introducción
Conceptos Previos
Leads:
“Leads” es un término comúnmente utilizado en el ámbito del marketing y ventas. Un “lead” se refiere a un individuo o entidad que ha mostrado interés en un producto o servicio, pero que aún no se ha convertido en cliente. Por lo general, un lead ha proporcionado cierta información de contacto (como un número de teléfono o una dirección de correo electrónico) que permite a una empresa seguir comunicándose con él o ella en un intento de convertir ese interés inicial en una venta.
Contacto Efectivo:
El término “Contacto Efectivo (CE)” generalmente se refiere a un contacto exitoso con un lead en el cual se cumple el objetivo previsto. Aquí algunos ejemplos de lo que podría considerarse un “contacto efectivo”:
- Si el objetivo es simplemente verificar la validez de un número telefónico, entonces un “contacto efectivo” podría ser cuando el titular contesta la llamada.
- Si el objetivo es vender un producto o servicio, entonces un “contacto efectivo” podría ser cuando el lead muestra un interés genuino o realiza una compra.
- Si el objetivo es recopilar información o hacer una encuesta, un “contacto efectivo” podría ser cuando el lead responde satisfactoriamente a las preguntas.
En este proyecto se considera que el contacto fue efectivo si el titular contestó la llamada.
Planteamiento del Problema
Actualmente Interbank es uno de los bancos más grandes y reconocidos de Perú. Interbank ofrece una amplia gama de productos y servicios financieros, que incluyen cuentas de ahorro y corriente, créditos hipotecarios, préstamos personales, tarjetas de crédito, seguros, entre otros.
La contactabilidad es un componente esencial en la operación de un banco. El no tener contactos efectivos, en particular en una institución financiera como Interbank, puede generar una serie de inconvenientes y problemas tanto para la entidad como para sus clientes. Estos son algunos de los problemas que podrían surgir:
Pérdida de Oportunidades de Negocio: No poder contactar eficazmente a los clientes significa perder oportunidades de ofrecer nuevos productos, servicios o promociones que podrían ser beneficiosos tanto para el banco como para el cliente.
Dificultades en la Gestión de Créditos: Si un cliente ha solicitado un crédito o tiene pagos pendientes, la falta de comunicación podría resultar en morosidades o malentendidos que afecten la salud financiera del cliente y el portafolio de crédito del banco.
Ineficiencia Operativa: Cada intento fallido de contacto implica un costo en términos de tiempo y recursos. Aumentar la eficiencia en la contactabilidad puede traducirse en ahorros significativos para la entidad.
Insatisfacción del Cliente: Si un cliente espera ser contactado para resolver una duda, recibir una oferta o simplemente para confirmar algún dato y no recibe la llamada, esto puede generar insatisfacción y afectar la percepción de servicio.
Limitación en Actualizaciones y Notificaciones: Muchas veces, los bancos necesitan comunicarse con los clientes para informar sobre cambios en los términos y condiciones, actualizaciones en políticas, o simplemente para notificar sobre movimientos importantes en sus cuentas.
Problemas de Seguridad y Fraude: La comunicación efectiva es esencial para confirmar transacciones sospechosas o para verificar la identidad del titular. La falta de contacto efectivo puede exponer tanto al banco como al cliente a riesgos de fraude.
Percepción de Mercado: En un mercado competitivo, la eficiencia en la comunicación y el servicio al cliente son factores clave de diferenciación. Una deficiente tasa de contactabilidad puede afectar negativamente la imagen del banco frente a sus competidores.
Dificultades en Estrategias de Retención: La contactabilidad efectiva es esencial para ejecutar estrategias de retención. Si un cliente está considerando cerrar una cuenta o dejar un servicio, una comunicación efectiva podría hacer la diferencia para retenerlo.
Fin
Mejorar la eficiencia del proceso de contacto telefónico.
Objetivo
Predecir cuáles números telefónicos tienen la mayor probabilidad de resultar en un CE antes de intentar establecer contacto telefónico.
Importancia
Optimizar la capacidad de contactar a los clientes de manera efectiva puede traducirse en: * mejorar la experiencia del cliente, * mejoras operativas, * mayores ingresos, * reducción de riesgos y * una mejor relación con el cliente.
Importanción de paquetes
Adquisición de la base de datos
Fuente de los datos
- Los conjuntos de datos utilizados en este proyecto fueron proporcionados por “Interbank” (supuesto).
- Los conjuntos de datos proporcionados fueron:
- data_selec_entre: base de datos de entrenamiento
- data_selec_test: base de datos de prueba
- La base de datos incluye variables que describen tanto características del cliente como historiales de contacto.
Consideraciones
- Los conjuntos de datos presentan 40 variables.
- En ambos conjuntos de datos, los valores
-999representan nulos.
Diccionario de Variables
| # | Variable | Descripción |
|---|---|---|
| 1 | TOTGEST6 | Cuantas gestiones se le realizo a la persona últimos 6 meses |
| 2 | TOTGEST12 | Cuantas gestiones se le realizo a la persona últimos 12 meses |
| 3 | TARGET | 1: contacto efectivo y 0: no contacto efectivo |
| 4 | SEGMENTO | Segmento |
| 5 | RECENCIA_APP | Hace cuanto tiempo has transaccionado con el APP |
| 6 | RANGO_INGRESOS | Rango de ingreso |
| 7 | PROVINCIA | Provincia del cliente |
| 8 | NUMPRIORIZACION | De donde vino el teléfono (tienda, cajero,compra de datos), regla para definir que tan priorizado es tu teléfono, toma en cuenta al mejor canal |
| 9 | NT_DISTR6 | Distribición de no tipificados (no se registra la tipificación) los últimos 6 meses |
| 10 | NT_DISTR12 | Distribición de no tipificados (no se registra la tipificación) los últimos 12 meses |
| 11 | NT_DIAS6 | Dias de la no tipificación los último 6 meses |
| 12 | NT_DIAS12 | Dias de la no tipificación los último 12 meses |
| 13 | NT_CTD6 | Cantidad de no tipificaciones los últimos 6 meses |
| 14 | NT_CTD12 | Cantidad de no tipificaciones los últimos 12 meses |
| 15 | NC_DISTR12 | % Distribución del no contacto en los 12 último meses |
| 16 | NC_DIAS6 | Días de no contacto en los último 6 meses |
| 17 | NC_DIAS12 | Días de no contacto en los último 12 meses |
| 18 | NC_CTD6 | Cantidad de no contacto en los últimos 6 meses |
| 19 | NC_CTD12 | Cantidad de no contacto en los últimos 12 meses |
| 20 | INGRESO_NETO_VIGENTE | Ingreso neto |
| 21 | INGRESO_BRUTO | Ingreso bruto |
| 22 | IDGRUPO | Es similar al número de priorización, pero solo muestra la fuente por donde vino tu dato |
| 23 | FEC_LLAMADA | Fecha de llamada |
| 24 | FBK_ULT6 | Ultimo Feedback de lo que ocurrio en los útimos 6 meses |
| 25 | FBK_ULT12 | Ultimo Feedback de lo que ocurrio en los útimos 12 meses |
| 26 | FBK_BEST6 | El mejor resultado de los último 6 meses |
| 27 | FBK_BEST12 | El mejor resultado de los último 12 meses |
| 28 | DIAS_ULT6 | Dias del de último feedback de los útimo 6 meses |
| 29 | DIAS_ULT12 | Dias del de último feedback de los útimo 12 meses |
| 30 | DIAS_BEST6 | Dias del mejor resultado de los útimo 6 meses |
| 31 | DIAS_BEST12 | Dias del mejor resultado de los útimo 12 meses |
| 32 | DIAS_ACT | Cuanto ha sido la cantidad de día que ha sido activo el telefono, es como una resencia |
| 33 | DEPARTAMENTO | Departamento del cliente |
| 34 | COD_SALA | Codigo de la sala que se llama al teléfono |
| 35 | CNE_DISTR6 | Distribución del contacto no efectivo los últimos 6 meses |
| 36 | CNE_DISTR12 | Distribución del contacto no efectivo los últimos 12 meses |
| 37 | CNE_DIAS6 | Días de contactos no efectivos útimos 6 meses |
| 38 | CNE_DIAS12 | Días de contactos no efectivos útimos 12 meses |
| 39 | CNE_CTD6 | Cantidad de contactos no efectivos útimos 6 meses |
| 40 | CNE_CTD12 | Cantidad de contactos no efectivos útimos 12 meses |
Descripción General
Variable Objetivo
TARGET: \[ TARGET = \begin{cases} 1 & \text{if } \text{el contacto fue efectivo} \\ 0 & \text{if } \text{el contacto no fue efectivo} \end{cases} \]
Recuerde que el término efectivo se refiere a la contestación por parte del titular del teléfono.
Variables Predictoras
Historial de Gestiones:
Tienes variables que indican cuántas veces se ha intentado contactar a un lead en distintos períodos de tiempo (TOTGEST6 y TOTGEST12).
Información Demográfica del Cliente:
La base de datos incluye información geográfica del cliente, como la PROVINCIA y el DEPARTAMENTO.
Información Financiera:
Se incluye información sobre los ingresos del cliente, tanto netos como brutos (RANGO_INGRESOS, INGRESO_NETO_VIGENTE, INGRESO_BRUTO).
Historial de Contactos y Resultados:
Tienes una serie de variables que rastrean no solo si se logró un contacto, sino también detalles sobre la naturaleza de esos contactos. Esto incluye datos sobre contactos que no fueron tipificados, contactos no exitosos y el feedback asociado a esos contactos.
Segmentación y Prioridad:
La base contiene información sobre la segmentación del cliente (SEGMENTO), la prioridad del número telefónico (NUMPRIORIZACION), y la fuente del número telefónico (IDGRUPO).
Interacción Digital:
Hay una variable (RECENCIA_APP) que parece indicar la reciente interacción del cliente con una aplicación, posiblemente una aplicación móvil o una plataforma digital.
Detalles Específicos del Contacto:
Se ha registrado información como la fecha de la llamada (FEC_LLAMADA) y el código de la sala desde donde se realizó la llamada (COD_SALA).
| Categoría | # | Variable | Descripción |
|---|---|---|---|
| Historial de Gestiones | 1 | TOTGEST6 | Cuantas gestiones se le realizo a la persona últimos 6 meses |
| Historial de Gestiones | 2 | TOTGEST12 | Cuantas gestiones se le realizo a la persona últimos 12 meses |
| Información Demográfica | 7 | PROVINCIA | Provincia del cliente |
| Información Demográfica | 33 | DEPARTAMENTO | Departamento del cliente |
| Información Financiera | 6 | RANGO_INGRESOS | Rango de ingreso |
| Información Financiera | 20 | INGRESO_NETO_VIGENTE | Ingreso neto |
| Información Financiera | 21 | INGRESO_BRUTO | Ingreso bruto |
| Historial de Contactos | 9 | NT_DISTR6 | Distribución de no tipificados (no se registra la tipificación) los últimos 6 meses |
| Historial de Contactos | 10 | NT_DISTR12 | Distribición de no tipificados (no se registra la tipificación) los últimos 12 meses |
| Historial de Contactos | 11 | NT_DIAS6 | Dias de la no tipificación los último 6 meses |
| Historial de Contactos | 12 | NT_DIAS12 | Dias de la no tipificación los último 12 meses |
| Historial de Contactos | 13 | NT_CTD6 | Cantidad de no tipificaciones los últimos 6 meses |
| Historial de Contactos | 14 | NT_CTD12 | Cantidad de no tipificaciones los últimos 12 meses |
| Historial de Contactos | 15 | NC_DISTR12 | % Distribución del no contacto en los 12 último meses |
| Historial de Contactos | 16 | NC_DIAS6 | Días de no contacto en los último 6 meses |
| Historial de Contactos | 17 | NC_DIAS12 | Días de no contacto en los último 12 meses |
| Historial de Contactos | 18 | NC_CTD6 | Cantidad de no contacto en los últimos 6 meses |
| Historial de Contactos | 19 | NC_CTD12 | Cantidad de no contacto en los últimos 12 meses |
| Historial de Contactos | 24 | FBK_ULT6 | Ultimo Feedback de lo que ocurrio en los útimos 6 meses |
| Historial de Contactos | 25 | FBK_ULT12 | Ultimo Feedback de lo que ocurrio en los útimos 12 meses |
| Historial de Contactos | 26 | FBK_BEST6 | El mejor resultado de los último 6 meses |
| Historial de Contactos | 27 | FBK_BEST12 | El mejor resultado de los último 12 meses |
| Historial de Contactos | 28 | DIAS_ULT6 | Dias del de último feedback de los útimo 6 meses |
| Historial de Contactos | 29 | DIAS_ULT12 | Dias del de último feedback de los útimo 12 meses |
| Historial de Contactos | 30 | DIAS_BEST6 | Dias del mejor resultado de los útimo 6 meses |
| Historial de Contactos | 31 | DIAS_BEST12 | Dias del mejor resultado de los útimo 12 meses |
| Historial de Contactos | 35 | CNE_DISTR6 | Distribución del contacto no efectivo los últimos 6 meses |
| Historial de Contactos | 36 | CNE_DISTR12 | Distribución del contacto no efectivo los últimos 12 meses |
| Historial de Contactos | 37 | CNE_DIAS6 | Días de contactos no efectivos útimos 6 meses |
| Historial de Contactos | 38 | CNE_DIAS12 | Días de contactos no efectivos útimos 12 meses |
| Historial de Contactos | 39 | CNE_CTD6 | Cantidad de contactos no efectivos útimos 6 meses |
| Historial de Contactos | 40 | CNE_CTD12 | Cantidad de contactos no efectivos útimos 12 meses |
| Segmentación y Prioridad | 4 | SEGMENTO | Segmento |
| Segmentación y Prioridad | 8 | NUMPRIORIZACION | De donde vino el teléfono (tienda, cajero, compra de datos), regla para definir que tan priorizado es tu teléfono, toma en cuenta al mejor canal |
| Segmentación y Prioridad | 22 | IDGRUPO | Es similar al número de priorización, pero solo muestra la fuente por donde vino tu dato |
| Interacción Digital | 5 | RECENCIA_APP | Hace cuanto tiempo has transaccionado con el APP |
| Detalles Específicos del Contacto | 23 | FEC_LLAMADA | Fecha de llamada |
| Detalles Específicos del Contacto | 34 | COD_SALA | Código de la sala que se llama al teléfono |
| Detalles Específicos del Contacto | 32 | DIAS_ACT | Cuanto ha sido la cantidad de día que ha sido activo el telefono, es como una recencia |
Importación de los datos
data_train = pd.read_csv("../data/raw/data_selec_entre.csv", na_values = [-999])
data_test = pd.read_csv("../data/raw/data_selec_test.csv", na_values = [-999])
data_train.head()| NUMPRIORIZACION | NC_DISTR12 | TOTGEST6 | TOTGEST12 | IDGRUPO | DIAS_ACT | FBK_ULT6 | FBK_ULT12 | FBK_BEST6 | DIAS_BEST6 | ... | NT_CTD6 | NT_DISTR6 | NT_DIAS6 | PROVINCIA | DEPARTAMENTO | INGRESO_NETO_VIGENTE | INGRESO_BRUTO | SEGMENTO | RANGO_INGRESOS | TARGET | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0.333333 | 6.0 | 6.0 | 3 | 118 | TLV | TLV | TLV | 8.0 | ... | NaN | NaN | NaN | TACNA | TACNA | 7136.0 | 9389.0 | 2 | Entre S/.4000-10000 | 1 |
| 1 | 1 | 0.461538 | 13.0 | 13.0 | 40 | 94 | TLV | TLV | TLV | 46.0 | ... | NaN | NaN | NaN | LIMA | LIMA | 6920.0 | 9105.0 | 1BC | Entre S/.4000-10000 | 1 |
| 2 | 1 | 0.666667 | 2.0 | 6.0 | 6 | 223 | TLV | TLV | TLV | 127.0 | ... | NaN | NaN | NaN | LIMA | LIMA | 1473.0 | 1655.0 | 2 | Entre S/.1000-4000 | 1 |
| 3 | 1 | NaN | 4.0 | 4.0 | 95 | 96 | TLV | TLV | TLV | 49.0 | ... | NaN | NaN | NaN | LIMA | LIMA | 2293.0 | 2729.0 | 2 | Entre S/.1000-4000 | 1 |
| 4 | 1 | 0.187500 | 10.0 | 16.0 | 4 | 91 | TLV | TLV | TLV | 27.0 | ... | NaN | NaN | NaN | CUSCO | CUSCO | 6470.0 | 8513.0 | 3 | Entre S/.4000-10000 | 1 |
5 rows × 40 columns
Navegando y limpiando los datos
Restricciones del tipo de datos
Identificación
Vamos a identificar si todas las variables se encuentran en el tipo de dato adecuado para su naturaleza. Esto implica determinar si las variables numéricas, categóricas, fechas y texto se encuentran en sus respectivos formatos.
# Obtén una serie con los tipos de datos de cada columna
data_types_series = data_train.dtypes
# Construye una lista de listas con los nombres de las columnas y los tipos de datos
data_types_list = [[col, data_types_series[col]] for col in data_types_series.index]
# Construye la tabla Markdown como una string
markdown_table = "| Variable | Tipo de Dato Actual |\n|----------|--------------|\n"
for row in data_types_list:
markdown_table += f"| {row[0]} | {row[1]} |\n"
# Imprime la tabla Markdown
print(markdown_table)| Variable | Tipo de Dato Actual |
|----------|--------------|
| NUMPRIORIZACION | int64 |
| NC_DISTR12 | float64 |
| TOTGEST6 | float64 |
| TOTGEST12 | float64 |
| IDGRUPO | int64 |
| DIAS_ACT | int64 |
| FBK_ULT6 | object |
| FBK_ULT12 | object |
| FBK_BEST6 | object |
| DIAS_BEST6 | float64 |
| DIAS_ULT6 | float64 |
| FBK_BEST12 | object |
| DIAS_BEST12 | float64 |
| DIAS_ULT12 | float64 |
| CNE_CTD12 | float64 |
| CNE_CTD6 | float64 |
| CNE_DIAS6 | float64 |
| CNE_DISTR6 | float64 |
| CNE_DISTR12 | float64 |
| CNE_DIAS12 | float64 |
| NC_CTD12 | float64 |
| NC_DIAS6 | float64 |
| NC_DIAS12 | float64 |
| NC_CTD6 | float64 |
| RECENCIA_APP | float64 |
| COD_SALA | object |
| NT_CTD12 | float64 |
| NT_DISTR12 | float64 |
| NT_DIAS12 | float64 |
| FEC_LLAMADA | object |
| NT_CTD6 | float64 |
| NT_DISTR6 | float64 |
| NT_DIAS6 | float64 |
| PROVINCIA | object |
| DEPARTAMENTO | object |
| INGRESO_NETO_VIGENTE | float64 |
| INGRESO_BRUTO | float64 |
| SEGMENTO | object |
| RANGO_INGRESOS | object |
| TARGET | int64 |
Para determinanar si los tipos de datos actuales son correctos o si debiésemos cambiarlos, observemos algunos valores que toman las observaciones:
data_train.head().T| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| NUMPRIORIZACION | 1 | 1 | 1 | 1 | 1 |
| NC_DISTR12 | 0.333333 | 0.461538 | 0.666667 | NaN | 0.1875 |
| TOTGEST6 | 6.0 | 13.0 | 2.0 | 4.0 | 10.0 |
| TOTGEST12 | 6.0 | 13.0 | 6.0 | 4.0 | 16.0 |
| IDGRUPO | 3 | 40 | 6 | 95 | 4 |
| DIAS_ACT | 118 | 94 | 223 | 96 | 91 |
| FBK_ULT6 | TLV | TLV | TLV | TLV | TLV |
| FBK_ULT12 | TLV | TLV | TLV | TLV | TLV |
| FBK_BEST6 | TLV | TLV | TLV | TLV | TLV |
| DIAS_BEST6 | 8.0 | 46.0 | 127.0 | 49.0 | 27.0 |
| DIAS_ULT6 | 8.0 | 9.0 | 127.0 | 49.0 | 27.0 |
| FBK_BEST12 | TLV | TLV | TLV | TLV | TLV |
| DIAS_BEST12 | 8.0 | 46.0 | 223.0 | 49.0 | 27.0 |
| DIAS_ULT12 | 8.0 | 9.0 | 127.0 | 49.0 | 27.0 |
| CNE_CTD12 | 1.0 | 4.0 | NaN | 2.0 | 3.0 |
| CNE_CTD6 | 1.0 | 4.0 | NaN | 2.0 | 1.0 |
| CNE_DIAS6 | 114.0 | 15.0 | NaN | 68.0 | 119.0 |
| CNE_DISTR6 | 0.166667 | 0.307692 | NaN | 0.5 | 0.1 |
| CNE_DISTR12 | 0.166667 | 0.307692 | NaN | 0.5 | 0.1875 |
| CNE_DIAS12 | 114.0 | 15.0 | NaN | 68.0 | 119.0 |
| NC_CTD12 | 2.0 | 6.0 | 4.0 | NaN | 3.0 |
| NC_DIAS6 | 58.0 | 9.0 | 127.0 | NaN | 140.0 |
| NC_DIAS12 | 58.0 | 9.0 | 127.0 | NaN | 140.0 |
| NC_CTD6 | 2.0 | 6.0 | 2.0 | NaN | 2.0 |
| RECENCIA_APP | 133.0 | NaN | NaN | NaN | NaN |
| COD_SALA | EC | PP | PA | NC | EC |
| NT_CTD12 | NaN | NaN | NaN | NaN | NaN |
| NT_DISTR12 | NaN | NaN | NaN | NaN | NaN |
| NT_DIAS12 | NaN | NaN | NaN | NaN | NaN |
| FEC_LLAMADA | 2018-02-08 | 2017-10-18 | 2018-02-13 | 2018-02-22 | 2017-11-07 |
| NT_CTD6 | NaN | NaN | NaN | NaN | NaN |
| NT_DISTR6 | NaN | NaN | NaN | NaN | NaN |
| NT_DIAS6 | NaN | NaN | NaN | NaN | NaN |
| PROVINCIA | TACNA | LIMA | LIMA | LIMA | CUSCO |
| DEPARTAMENTO | TACNA | LIMA | LIMA | LIMA | CUSCO |
| INGRESO_NETO_VIGENTE | 7136.0 | 6920.0 | 1473.0 | 2293.0 | 6470.0 |
| INGRESO_BRUTO | 9389.0 | 9105.0 | 1655.0 | 2729.0 | 8513.0 |
| SEGMENTO | 2 | 1BC | 2 | 2 | 3 |
| RANGO_INGRESOS | Entre S/.4000-10000 | Entre S/.4000-10000 | Entre S/.1000-4000 | Entre S/.1000-4000 | Entre S/.4000-10000 |
| TARGET | 1 | 1 | 1 | 1 | 1 |
Inspeccionamos los valores únicos que pueden tomar las variables de tipo object:
# Filtra las columnas que tienen tipo de dato 'object'
object_columns = data_train.select_dtypes(include='object').columns
# Obtén los valores únicos para cada columna y los almacena en un diccionario
unique_values = {}
for col in object_columns:
unique_values[col] = data_train[col].unique()
# Imprime los valores únicos
for col, values in unique_values.items():
print(f"{col}: {values}")FBK_ULT6: ['TLV' 'NULO' 'IVR' 'COB']
FBK_ULT12: ['TLV' 'NULO' 'IVR' 'COB']
FBK_BEST6: ['TLV' 'NULO' 'IVR' 'COB']
FBK_BEST12: ['TLV' 'NULO' 'IVR' 'COB']
COD_SALA: ['EC' 'PP' 'PA' 'NC' 'C' 'PRR' 'CD' 'CON' '2DA' 'UPG' 'IL' 'BPE' 'DIL'
'TC' nan 'DEF']
FEC_LLAMADA: ['2018-02-08' '2017-10-18' '2018-02-13' '2018-02-22' '2017-11-07'
'2017-11-17' '2017-09-18' '2018-02-23' '2017-10-16' '2017-10-06'
'2017-11-23' '2017-10-09' '2017-11-20' '2017-09-14' '2017-10-17'
'2017-10-11' '2017-11-15' '2017-10-25' '2017-09-26' '2017-10-30'
'2018-02-12' '2017-09-22' '2017-10-24' '2017-10-13' '2017-11-22'
'2017-10-04' '2017-09-27' '2017-10-26' '2017-11-03' '2018-02-09'
'2017-11-14' '2018-02-20' '2017-11-06' '2017-09-19' '2017-11-08'
'2018-02-19' '2018-02-01' '2018-02-21' '2017-11-21' '2018-02-06'
'2017-09-25' '2017-09-13' '2018-02-07' '2018-02-16' '2017-11-13'
'2017-10-27' '2017-10-10' '2017-10-05' '2017-09-20' '2017-10-31'
'2018-02-14' '2017-10-20' '2017-09-15' '2018-02-10' '2017-10-03'
'2017-11-24' '2017-10-19' '2017-09-12' '2018-02-15' '2017-11-09'
'2017-09-11' '2017-09-06' '2017-11-10' '2017-09-08' '2017-10-07'
'2017-09-05' '2017-11-16' '2017-10-12' '2017-11-18' '2017-09-01'
'2017-09-07' '2018-02-05' '2017-09-21' '2017-10-14' '2017-09-28'
'2017-09-04' '2018-02-02' '2017-11-25' '2018-02-24' '2017-11-02'
'2017-10-02' '2017-10-23' '2017-11-27' '2018-02-17' '2017-10-28'
'2017-10-21' '2017-08-07' '2017-09-16' '2017-07-17' '2017-09-09'
'2017-11-11' '2017-07-04' '2017-07-05' '2017-07-20' '2017-07-03'
'2017-08-03' '2017-09-23' '2017-07-24' '2017-07-10' '2017-08-21'
'2017-08-04' '2017-07-31' '2017-07-07' '2017-07-25' '2017-07-26'
'2017-11-19' '2017-07-14' '2017-07-27']
PROVINCIA: ['TACNA' 'LIMA' 'CUSCO' 'CAJAMARCA' 'AREQUIPA' 'TRUJILLO' 'CHICLAYO'
'PROV. CONST. DEL CALLAO' 'TUMBES' 'HUAMANGA' 'INF. NO DISPONIBLE'
'CARHUAZ' 'MARISCAL NIETO' 'ABANCAY' 'HUANUCO' 'PASCO' 'NAZCA' 'PIURA'
'HUANCAYO' 'TAMBOPATA' 'SANTA' 'CAMANA' 'CALCA' 'PUNO' 'CHUPACA'
'SAN ROMAN' 'PISCO' 'BARRANCA' 'HUAURA' 'HUARAZ' 'CORONEL PORTILLO' 'ICA'
'TALARA' 'SAN MARTIN' 'HUAROCHIRI' 'CASMA' 'MOYOBAMBA' 'MAYNAS' 'PAITA'
'SULLANA' 'ILO' 'CHANCHAMAYO' 'LAMBAYEQUE' 'URUBAMBA' 'HUANCAVELICA'
'CHINCHA' 'BAGUA' 'HUARAL' 'TARMA' 'SATIPO' 'MELGAR' 'RIOJA' 'JAEN'
'PACASMAYO' 'VIRU' 'LAMPA' 'CAJABAMBA' 'MARISCAL LUZURIAGA' 'CAYLLOMA'
'ZARUMILLA' 'YAUYOS' 'BELLAVISTA' 'JUNIN' 'TOCACHE' 'JAUJA' 'CAA`ETE'
'GENERAL SANCHEZ CERRO' 'ASCOPE' 'ANDAHUAYLAS' 'BOLIVAR' 'LA CONVENCION'
'SECHURA' 'HUANTA' 'TAYACAJA' 'SAN MARCOS' 'RODRIGUEZ DE MENDOZA' 'PALPA'
'ALTO AMAZONAS' 'CHEPEN' 'HUACAYBAMBA' 'MORROPON' 'LEONCIO PRADO'
'EL COLLAO' 'HUAYTARA' 'YAULI' 'LAMAS' 'AMBO' 'CONCEPCION' 'HUANCANE'
'UTCUBAMBA' 'SAN PABLO' 'OXAPAMPA' 'COTABAMBAS' 'CANETE' 'CASTILLA'
'LUYA' 'QUISPICANCHI' 'AZANGARO' 'ISLAY' 'ACOMAYO' 'ESPINAR' 'CARAVELI'
'CHINCHEROS' 'SAN MIGUEL' 'MARISCAL CACERES' 'CHACHAPOYAS' 'FERREA`AFE'
'RECUAY' 'CONTRALMIRANTE VILLAR' 'ASUNCION' 'SAN ANTONIO DE PUTINA'
'HUALGAYOC' 'CANTA' 'CHOTA' 'PUERTO INCA' 'CUTERVO' 'PADRE ABAD' 'LORETO'
'OTUZCO' 'GRAU' 'YUNGAY' 'BONGARA' 'PICOTA' 'PATAZ' 'ANGARAES' 'CELENDIN'
'SANCHEZ CARRION' 'AYABACA' 'ANTA' 'LA MAR' 'CANCHIS' 'CANGALLO' 'MANU'
'TAHUAMANU' 'CONTUMAZA' 'FERRENAFE' 'HUANCABAMBA' 'PARURO' 'CHUCUITO'
'POMABAMBA' 'CAJATAMBO' 'TARATA' 'ANTABAMBA' 'CANDARAVE' 'JORGE BASADRE'
'HUARI' 'DOS DE MAYO' 'OYON' 'MARISCAL RAMON CASTILLA' 'HUARMEY' 'SIHUAS'
'HUANCA SANCOS' 'ATALAYA' 'SAN IGNACIO' 'HUAMALIES' 'YUNGUYO' 'HUALLAGA'
'HUAYLAS' 'ACOBAMBA' 'LA UNION' 'CASTROVIRREYNA' 'BOLOGNESI' 'AIJA'
'YAROWILCA' 'GRAN CHIMU' 'UCAYALI' 'MOHO' 'DANIEL ALCIDES CARRION'
'LUCANAS' 'CONDESUYOS' 'PACHITEA' 'CANAS' 'SANDIA'
'CARLOS FERMIN FITZCARRALD' 'REQUENA' 'PARINACOCHAS' 'CARABAYA'
'SANTA CRUZ' 'SANTIAGO DE CHUCO' 'VILCAS HUAMAN' 'ANTONIO RAYMONDI'
'AYMARAES' 'CHUMBIVILCAS' 'CONDORCANQUI' 'EL DORADO' 'VICTOR FAJARDO'
'DATEM DEL MARAA`ON' 'PAUCARTAMBO' 'LAURICOCHA' 'OCROS' 'PALLASCA'
'PURUS']
DEPARTAMENTO: ['TACNA' 'LIMA' 'CUSCO' 'CAJAMARCA' 'AREQUIPA' 'LA LIBERTAD' 'LAMBAYEQUE'
'CALLAO' 'TUMBES' 'AYACUCHO' 'INF. NO DISPONIBLE' 'ANCASH' 'MOQUEGUA'
'APURIMAC' 'HUANUCO' 'PASCO' 'ICA' 'PIURA' 'JUNIN' 'MADRE DE DIOS' 'PUNO'
'UCAYALI' 'SAN MARTIN' 'LORETO' 'HUANCAVELICA' 'AMAZONAS']
SEGMENTO: ['2' '1BC' '3' '5' '4' '1A' 'NULO' '6']
RANGO_INGRESOS: ['Entre S/.4000-10000' 'Entre S/.1000-4000' 'Entre S/.600-1000'
'Mayor a S/.10000' 'Sin ingresos' 'Entre S/.0-600' 'NULO']Inspeccionamos los valores únicos que pueden tomar las variables NUMPRIORIZACION y IDGRUPO de tipo int64:
# Filtra las columnas que tienen tipo de dato 'object'
id_columns = ["NUMPRIORIZACION","IDGRUPO"]
# Obtén los valores únicos para cada columna y los almacena en un diccionario
unique_values = {}
for col in id_columns:
unique_values[col] = data_train[col].unique()
# Imprime los valores únicos
for col, values in unique_values.items():
print(f"{col}: {values}")NUMPRIORIZACION: [ 1 5 2 4 3 6 8 7 9 10]
IDGRUPO: [ 3 40 6 95 4 13 81 58 9 26 57 79 86 94 64 30 70 50 85 15 93 21 16 90
92 7 11 62 68 18 38 24 78 23 10 28 2 27 87 63 55 14 71 67 72 89 35 66
91 5 29 22 56 19 61 12 60 65]Dado que la variable NUMPRIORIZACION toma valores discretos entre 1 y 10 y la variable IDGRUPO según el diccionario de variables es similar al númer de priorización, decidimos convertir estas dos variables a tipo category:
for data in data_train, data_test:
id_columns = ["NUMPRIORIZACION","IDGRUPO"]
data[id_columns] = data[id_columns].astype('category')Advertencia: La variable IDGRUPO tiene muchas categorías que muestran la fuente por donde vino el dato. La dificultad radica en que no se conoce el significado de cada una de estas categorías. Por lo tanto, se decide eliminar esta variable.
for data in data_train, data_test:
data.drop('IDGRUPO', axis=1, inplace=True)Dado que el diccionario de variables describe a las siguientes variables como: * CNE_DIAS: “Días de contactos no efectivos útimos 6 meses” * CNE_DIAS1: “Días de contactos no efectivos útimos 12 meses” * NC_DIAS: Días de no contacto en los último 6 meses * NC_DIAS1: Días de no contacto en los último 12 meses se puede inferir que los valores que toman estas variables son categorías referidas a días. Hagamos una inspección de los valores únicos que toman estas variables:
dias_columns = ["CNE_DIAS6","CNE_DIAS12","NC_DIAS6","NC_DIAS12"]
# Obtén los valores únicos para cada columna y los almacena en un diccionario
unique_values = {}
for col in dias_columns:
unique_values[col] = data_train[col].unique()
# Imprime los valores únicos
for col, values in unique_values.items():
print(f"{col}: {values}")CNE_DIAS6: [114. 15. nan 68. 119. 26. 80. 183. 21. 130. 118. 17. 156. 24.
2. 138. 77. 59. 22. 14. 116. 131. 189. 12. 23. 107. 126. 55.
188. 127. 28. 16. 54. 40. 111. 176. 115. 33. 53. 162. 134. 47.
20. 60. 70. 82. 147. 145. 90. 97. 51. 8. 18. 94. 104. 163.
37. 143. 173. 86. 56. 44. 164. 49. 4. 180. 89. 41. 199. 195.
175. 100. 144. 72. 78. 79. 92. 168. 210. 85. 1. 113. 167. 48.
43. 73. 66. 5. 135. 98. 6. 178. 202. 120. 25. 193. 165. 19.
209. 7. 84. 123. 50. 69. 0. 105. 45. 157. 42. 146. 99. 58.
171. 34. 160. 133. 65. 108. 63. 67. 204. 191. 148. 39. 52. 57.
11. 161. 9. 10. 155. 81. 141. 36. 128. 93. 27. 71. 3. 61.
177. 166. 132. 74. 197. 142. 112. 32. 190. 122. 153. 203. 140. 194.
211. 13. 38. 212. 154. 208. 170. 76. 106. 35. 91. 110. 46. 64.
136. 169. 83. 101. 30. 200. 174. 87. 29. 117. 151. 102. 181. 109.
96. 205. 182. 31. 88. 184. 158. 103. 179. 124. 185. 198. 95. 159.
186. 75. 192. 129. 196. 152. 187. 137. 172. 201. 125. 149. 139. 206.
121. 207. 62. 150. 214. 213.]
CNE_DIAS12: [114. 15. nan 68. 119. 26. 80. 183. 21. 130. 118. 17. 156. 24.
2. 138. 77. 59. 22. 218. 14. 116. 131. 189. 12. 23. 107. 126.
55. 188. 127. 28. 16. 54. 40. 111. 176. 115. 33. 53. 227. 279.
384. 162. 134. 47. 20. 60. 70. 82. 147. 145. 90. 97. 51. 8.
18. 251. 94. 250. 104. 219. 163. 233. 224. 37. 143. 173. 86. 56.
44. 292. 221. 164. 49. 4. 180. 89. 41. 199. 195. 175. 100. 144.
257. 72. 78. 79. 92. 168. 210. 85. 1. 113. 296. 287. 167. 48.
43. 267. 73. 213. 222. 66. 5. 135. 98. 6. 178. 202. 120. 25.
193. 165. 19. 209. 7. 84. 123. 50. 69. 0. 271. 105. 45. 299.
255. 242. 157. 232. 42. 146. 99. 372. 58. 171. 34. 160. 133. 65.
301. 108. 63. 67. 204. 191. 148. 263. 39. 52. 57. 288. 11. 161.
9. 309. 10. 280. 155. 81. 316. 307. 141. 36. 128. 93. 27. 71.
3. 61. 177. 166. 298. 132. 74. 357. 265. 315. 197. 142. 320. 112.
32. 190. 236. 342. 289. 327. 122. 153. 203. 358. 378. 379. 140. 194.
211. 13. 356. 254. 228. 38. 212. 154. 240. 258. 239. 216. 300. 208.
170. 286. 76. 106. 308. 349. 262. 35. 91. 110. 46. 235. 64. 136.
169. 83. 310. 306. 390. 101. 249. 314. 30. 385. 200. 174. 87. 29.
277. 117. 369. 151. 102. 226. 238. 223. 181. 109. 343. 260. 96. 205.
338. 182. 383. 31. 337. 88. 184. 158. 245. 229. 103. 392. 179. 328.
124. 185. 198. 95. 248. 159. 256. 186. 75. 237. 321. 281. 234. 192.
344. 243. 387. 269. 230. 129. 371. 261. 231. 290. 247. 196. 355. 272.
152. 225. 259. 330. 341. 246. 187. 273. 331. 214. 215. 365. 278. 137.
270. 217. 352. 285. 348. 350. 172. 329. 201. 125. 253. 149. 241. 284.
324. 334. 294. 313. 139. 373. 206. 370. 121. 323. 252. 207. 391. 266.
282. 295. 345. 264. 366. 297. 220. 293. 386. 322. 340. 303. 362. 268.
274. 333. 62. 283. 375. 150. 291. 380. 317. 377. 335. 376. 347. 302.
319. 244. 359. 361. 351. 368. 276. 312. 382. 354. 364. 336. 393. 326.
305. 394. 389. 275. 363.]
NC_DIAS6: [ 58. 9. 127. nan 140. 82. 33. 149. 8. 184. 1. 18. 80. 32.
0. 26. 16. 2. 23. 5. 120. 4. 20. 44. 103. 78. 70. 145.
19. 51. 13. 6. 15. 112. 81. 100. 108. 126. 29. 7. 34. 30.
113. 199. 185. 40. 132. 52. 60. 97. 98. 27. 57. 205. 25. 207.
156. 135. 35. 77. 56. 47. 73. 55. 146. 36. 24. 138. 102. 72.
88. 12. 96. 92. 43. 131. 39. 158. 22. 154. 66. 189. 28. 85.
174. 123. 137. 111. 42. 68. 86. 3. 134. 37. 94. 61. 67. 54.
191. 48. 49. 144. 10. 166. 50. 157. 41. 17. 125. 107. 193. 186.
128. 155. 89. 115. 201. 71. 161. 182. 83. 31. 11. 162. 129. 79.
95. 75. 106. 87. 192. 114. 38. 187. 188. 21. 14. 133. 65. 164.
163. 63. 124. 117. 109. 76. 203. 180. 74. 46. 147. 45. 175. 69.
143. 84. 142. 150. 53. 141. 136. 168. 99. 152. 173. 195. 190. 160.
167. 101. 181. 196. 118. 105. 110. 148. 165. 211. 204. 90. 122. 209.
197. 172. 119. 104. 183. 116. 153. 179. 202. 208. 212. 139. 93. 170.
64. 176. 177. 194. 62. 130. 121. 91. 169. 210. 159. 198. 151. 178.
206. 59. 200. 171. 213. 214. 240.]
NC_DIAS12: [ 58. 9. 127. nan 140. 82. 33. 149. 8. 184. 1. 18. 80. 32.
0. 26. 16. 2. 23. 5. 120. 4. 20. 44. 103. 78. 70. 145.
225. 19. 51. 13. 6. 15. 112. 81. 100. 108. 126. 29. 7. 34.
30. 113. 199. 185. 40. 132. 52. 60. 97. 98. 260. 27. 57. 205.
25. 207. 156. 135. 35. 77. 56. 47. 73. 55. 146. 36. 24. 138.
102. 72. 88. 12. 96. 254. 92. 213. 43. 131. 39. 158. 22. 154.
66. 189. 245. 28. 349. 85. 174. 123. 137. 111. 42. 68. 350. 86.
3. 215. 134. 37. 298. 308. 94. 384. 61. 223. 265. 67. 54. 191.
270. 48. 49. 144. 253. 267. 10. 166. 50. 157. 41. 17. 125. 107.
193. 186. 128. 155. 89. 220. 115. 201. 71. 161. 182. 295. 83. 31.
338. 11. 162. 129. 257. 317. 79. 232. 95. 230. 75. 315. 385. 106.
87. 192. 256. 114. 38. 187. 188. 21. 14. 133. 65. 237. 164. 163.
228. 63. 124. 117. 109. 76. 203. 293. 258. 180. 74. 239. 46. 216.
273. 147. 45. 175. 69. 250. 326. 246. 143. 84. 142. 150. 379. 271.
226. 53. 141. 136. 168. 218. 99. 221. 247. 152. 287. 173. 195. 190.
229. 281. 160. 167. 233. 320. 370. 101. 181. 252. 234. 196. 118. 105.
110. 365. 148. 392. 280. 165. 240. 342. 231. 211. 316. 204. 90. 122.
209. 197. 172. 243. 119. 313. 104. 183. 288. 116. 153. 179. 202. 264.
327. 208. 330. 212. 278. 139. 362. 262. 299. 93. 236. 259. 279. 263.
219. 296. 322. 294. 248. 387. 170. 242. 64. 176. 307. 366. 224. 249.
177. 194. 217. 282. 222. 336. 62. 130. 251. 373. 121. 235. 91. 266.
277. 169. 291. 214. 210. 286. 340. 159. 238. 344. 272. 352. 255. 300.
372. 198. 151. 329. 355. 359. 268. 261. 241. 178. 319. 227. 321. 351.
206. 337. 309. 375. 328. 59. 284. 383. 285. 341. 200. 380. 301. 306.
348. 378. 377. 324. 289. 171. 314. 369. 361. 335. 310. 371. 343. 274.
390. 357. 292. 269. 244. 290. 358. 334. 323. 376. 302. 333. 345. 354.
382. 283. 386. 331. 347. 391. 368. 297. 356. 312. 276. 303. 363. 364.
275. 305.]Sin embargo, esta inspección muestra que estas variables se refieren a cantidades de días. Por ende, el tipo de datos de cada uno de estas variables es int64. Aunque se están dejando como float64 para poder realizar operaciones con ellas.
La variable FEC_LLAMADA es de tipo object pero debería ser de tipo datetime.
# Convertir la columna a datetime usando el formato especificado
for data in data_train, data_test:
data['FEC_LLAMADA'] = pd.to_datetime(data['FEC_LLAMADA'], format='%Y-%m-%d')data_train['FEC_LLAMADA'].head()0 2018-02-08
1 2017-10-18
2 2018-02-13
3 2018-02-22
4 2017-11-07
Name: FEC_LLAMADA, dtype: datetime64[ns]El resto de variables del tipo object deben ser convertidas al tipo de dato category:
# Convertir todas las columnas de tipo 'object' a 'category'
for data in data_train, data_test:
cols_object = data.select_dtypes(include=['object']).columns
data[cols_object] = data[cols_object].astype('category')Aunque sería recomendable convertir algunas variables del tipo float64 a int64, en este caso no lo haremos porque no es necesario.
En resumen, los tipos de datos que las variables toman y deberían tomar (las cuales en realidad ya fueron establecidas) son:
| Tipo de Dato Actual | Tipo de Dato Recomendado | # | Variable | Descripción |
|---|---|---|---|---|
| float64 | int64 | 1 | TOTGEST6 | Cuantas gestiones se le realizo a la persona últimos 6 meses |
| float64 | int64 | 2 | TOTGEST12 | Cuantas gestiones se le realizo a la persona últimos 12 meses |
| float64 | int64 | 13 | NT_CTD6 | Cantidad de no tipificaciones los últimos 6 meses |
| float64 | int64 | 14 | NT_CTD12 | Cantidad de no tipificaciones los últimos 12 meses |
| float64 | int64 | 18 | NC_CTD6 | Cantidad de no contacto en los últimos 6 meses |
| float64 | int64 | 19 | NC_CTD12 | Cantidad de no contacto en los últimos 12 meses |
| float64 | int64 | 39 | CNE_CTD6 | Cantidad de contactos no efectivos últimos 6 meses |
| float64 | int64 | 40 | CNE_CTD12 | Cantidad de contactos no efectivos últimos 12 meses |
| float64 | float64 | 20 | INGRESO_NETO_VIGENTE | Ingreso neto |
| float64 | float64 | 21 | INGRESO_BRUTO | Ingreso bruto |
| float64 | float64 | 9 | NT_DISTR6 | Distribución de no tipificados últimos 6 meses |
| float64 | float64 | 10 | NT_DISTR12 | Distribución de no tipificados últimos 12 meses |
| float64 | float64 | 11 | NT_DIAS6 | Dias de la no tipificación los último 6 meses |
| float64 | float64 | 12 | NT_DIAS12 | Dias de la no tipificación los último 12 meses |
| float64 | float64 | 15 | NC_DISTR12 | % Distribución del no contacto en los 12 último meses |
| float64 | float64 | 16 | NC_DIAS6 | Días de no contacto en los último 6 meses |
| float64 | float64 | 17 | NC_DIAS12 | Días de no contacto en los último 12 meses |
| float64 | float64 | 28 | DIAS_ULT6 | Dias del de último feedback de los últimos 6 meses |
| float64 | float64 | 29 | DIAS_ULT12 | Dias del de último feedback de los últimos 12 meses |
| float64 | float64 | 30 | DIAS_BEST6 | Dias del mejor resultado de los últimos 6 meses |
| float64 | float64 | 31 | DIAS_BEST12 | Dias del mejor resultado de los últimos 12 meses |
| float64 | float64 | 35 | CNE_DISTR6 | Distribución del contacto no efectivo los últimos 6 meses |
| float64 | float64 | 36 | CNE_DISTR12 | Distribución del contacto no efectivo los últimos 12 meses |
| float64 | float64 | 37 | CNE_DIAS6 | Días de contactos no efectivos últimos 6 meses |
| float64 | float64 | 38 | CNE_DIAS12 | Días de contactos no efectivos últimos 12 meses |
| float64 | float64 | 5 | RECENCIA_APP | Hace cuanto tiempo has transaccionado con el APP |
| int64 | int64 | 32 | DIAS_ACT | Cuanto ha sido la cantidad de día que ha sido activo el teléfono, es como una recencia |
| object | datetime | 23 | FEC_LLAMADA | Fecha de llamada |
| int64 | category | 8 | NUMPRIORIZACION | De donde vino el teléfono (tienda, cajero, compra de datos), regla para definir que tan priorizado es tu teléfono |
| int64 | category | 22 | IDGRUPO | Es similar al número de priorización, pero solo muestra la fuente por donde vino tu dato |
| object | category | 7 | PROVINCIA | Provincia del cliente |
| object | category | 33 | DEPARTAMENTO | Departamento del cliente |
| object | category | 6 | RANGO_INGRESOS | Rango de ingreso |
| object | category | 24 | FBK_ULT6 | Ultimo Feedback de lo que ocurrio en los últimos 6 meses |
| object | category | 25 | FBK_ULT12 | Ultimo Feedback de lo que ocurrio en los últimos 12 meses |
| object | category | 26 | FBK_BEST6 | El mejor resultado de los último 6 meses |
| object | category | 27 | FBK_BEST12 | El mejor resultado de los último 12 meses |
| object | category | 4 | SEGMENTO | Segmento |
| int64 | category | 3 | TARGET | 1: contacto efectivo y 0: no contacto efectivo |
| object | category | 34 | COD_SALA | Código de la sala que se llama al teléfono |
Tratamiento de valores valtantes
Identificamos variables con valores faltantes:
# Cantidad de valores faltantes por variable
missing_counts = data_train.isnull().sum()
# Frecuencia de valores faltantes por variable
missing_freq = data_train.isnull().mean() * 100
# Filtrar solo las columnas con valores faltantes
missing_data = pd.DataFrame({'Missing Count': missing_counts, 'Missing Frequency (%)': missing_freq})
missing_data = missing_data[missing_data['Missing Count'] > 0].sort_values(by='Missing Count', ascending=False)
print(missing_data) Missing Count Missing Frequency (%)
NT_DIAS6 722212 95.355239
NT_DISTR6 722212 95.355239
NT_CTD6 722212 95.355239
NT_DIAS12 706221 93.243912
NT_DISTR12 706221 93.243912
NT_CTD12 706221 93.243912
RECENCIA_APP 681465 89.975323
CNE_CTD6 496789 65.592145
CNE_DIAS6 496789 65.592145
CNE_DISTR6 496789 65.592145
CNE_CTD12 455346 60.120334
CNE_DISTR12 455346 60.120334
CNE_DIAS12 455346 60.120334
NC_CTD6 283215 37.393500
NC_DIAS6 283215 37.393500
NC_DISTR12 249939 32.999996
NC_CTD12 249939 32.999996
NC_DIAS12 249939 32.999996
TOTGEST6 191950 25.343581
DIAS_ULT6 191950 25.343581
DIAS_BEST6 191950 25.343581
DIAS_ULT12 169506 22.380250
DIAS_BEST12 169506 22.380250
TOTGEST12 169506 22.380250
INGRESO_NETO_VIGENTE 1360 0.179564
INGRESO_BRUTO 1360 0.179564
COD_SALA 3 0.000396La decisión que tomaremos para el tratamiento de valores faltantes es la siguiente:
- Eliminación de Variables:
- Si una variable tiene una alta proporción de valores faltantes (por ejemplo, más del 90%), es posible que no proporcione información significativa, por lo que podría considerar eliminarla.
- En este caso, variables como
NT_DIAS6,NT_DISTR6,NT_CTD6,NT_DIAS12,NT_DISTR12,NT_CTD12, yRECENCIA_APPtienen altas frecuencias de valores faltantes y podrían ser candidatos para eliminación.
- Imputación:
- Para variables con una proporción moderada de valores faltantes (por ejemplo, entre el 20% y el 90%), podría considerar la imputación. Las técnicas de imputación varían según el tipo de datos.
- Para variables numéricas: Puedes usar la media, la mediana o incluso modelos más avanzados para imputar (como k-NN o modelos de regresión).
- Para variables categóricas: Puedes usar la moda o técnicas de imputación basadas en modelos.
- En tu caso, variables como
CNE_CTD6,CNE_DIAS6,CNE_DISTR6,CNE_CTD12,CNE_DISTR12,CNE_DIAS12,NC_CTD6,NC_DIAS6,NC_DISTR12,NC_CTD12,NC_DIAS12,TOTGEST6,DIAS_ULT6,DIAS_BEST6,DIAS_ULT12,DIAS_BEST12, yTOTGEST12podrían beneficiarse de la imputación.
- Para variables con una proporción moderada de valores faltantes (por ejemplo, entre el 20% y el 90%), podría considerar la imputación. Las técnicas de imputación varían según el tipo de datos.
- Tratamiento de Valores Faltantes Pequeños:
- Si la proporción de valores faltantes es muy pequeña (por ejemplo, menos del 5%), podrías considerar varias estrategias:
- Imputar con métodos simples (media, mediana, moda).
- Eliminar las observaciones con valores faltantes.
- Para
INGRESO_NETO_VIGENTE,INGRESO_BRUTO, yCOD_SALA, podrías utilizar una de estas estrategias.
- Si la proporción de valores faltantes es muy pequeña (por ejemplo, menos del 5%), podrías considerar varias estrategias:
Aplicamos nuestra decisión de tratamiento:
Eliminado variables con una frecuencia de valores perdidos mayor o igual al 90%:
# Identificar columnas con una frecuencia de valores perdidos mayor o igual al 90%
cols_a_eliminar = data_train.columns[data.isnull().mean() >= 0.89]
print(cols_a_eliminar)Index(['RECENCIA_APP', 'NT_CTD12', 'NT_DISTR12', 'NT_DIAS12', 'NT_CTD6',
'NT_DISTR6', 'NT_DIAS6'],
dtype='object')# Eliminar las columnas identificadas
for data in data_train, data_test:
data = data.drop(cols_a_eliminar, axis=1)Aplicamos las estrategias de imputación en variables numéricas:
Para aquellas variables numéricas con una frecuencia de valores perdidos entre 20% y 90%, se realiza la imputación por k-MM. Sin embargo por ser un proceso que consume mucha memoria RAM y se ejecuta en bastante tiempo, se facilita el código para ello, pero no se hará esta técnica de imputación. Por cuestiones de recursos se utilizará imputación por la media o mediana.
#from fancyimpute import KNN
# Identifica las columnas numéricas con una frecuencia de valores perdidos entre 20% y 89%
#cols_a_imputar = data.columns[(data.isnull().mean() >= 0.20) & (data.isnull().mean() <= 0.89) & (data.dtypes != 'O')]
# Imputación usando k-NN
#knn_imputer = KNN(k=5) # puedes ajustar el valor de k si lo deseas
#data[cols_a_imputar] = knn_imputer.fit_transform(data[cols_a_imputar])Para aquellas variables numéricas con una frecuencia de valores perdidos menores de 5%, también se realiza la imputación por la media o mediana.
from scipy.stats import skew
# Filtrar variables numéricas
numeric_features = data_train.select_dtypes(include=['float64', 'int64'])
# Calcular asimetría para cada variable numérica
skew_values = numeric_features.apply(lambda x: skew(x.dropna())).sort_values(ascending=False)
# Variables con distribución aproximadamente normal (puedes ajustar el umbral según lo que consideres "cercano a 0")
normal_vars = skew_values[abs(skew_values) < 0.5].index.tolist()
# Variables asimétricas
asymmetric_vars = skew_values[abs(skew_values) >= 0.5].index.tolist()
print("Variables con distribución aproximadamente normal:", normal_vars)
print("Variables asimétricas:", asymmetric_vars)Variables con distribución aproximadamente normal: ['NT_DIAS12', 'NC_DISTR12', 'NT_DIAS6']
Variables asimétricas: ['INGRESO_BRUTO', 'INGRESO_NETO_VIGENTE', 'DIAS_ACT', 'NT_DISTR12', 'RECENCIA_APP', 'NT_CTD6', 'NT_DISTR6', 'NT_CTD12', 'NC_CTD6', 'CNE_CTD6', 'NC_CTD12', 'CNE_CTD12', 'DIAS_ULT12', 'TOTGEST12', 'TOTGEST6', 'DIAS_ULT6', 'CNE_DISTR12', 'CNE_DISTR6', 'DIAS_BEST12', 'NC_DIAS12', 'DIAS_BEST6', 'NC_DIAS6', 'CNE_DIAS12', 'CNE_DIAS6', 'TARGET']# Imputar las variables con distribución aproximadamente normal con la media
for data in data_train, data_test:
for var in normal_vars:
mean_value = data[var].mean()
data[var].fillna(mean_value, inplace=True)
# Imputar las variables asimétricas con la mediana
for var in asymmetric_vars:
median_value = data[var].median()
data[var].fillna(median_value, inplace=True)Verificación:
# Cantidad de valores faltantes por variable
missing_counts = data_train.isnull().sum()
# Frecuencia de valores faltantes por variable
missing_freq = data_train.isnull().mean() * 100
# Filtrar solo las columnas con valores faltantes
missing_data = pd.DataFrame({'Missing Count': missing_counts, 'Missing Frequency (%)': missing_freq})
missing_data = missing_data[missing_data['Missing Count'] > 0].sort_values(by='Missing Count', ascending=False)
print(missing_data) Missing Count Missing Frequency (%)
COD_SALA 3 0.000396Eliminamos las observaciones restantes con valores faltantes:
for data in data_train, data_test:
data.dropna(inplace=True)Ahora imputamos las variables categóricas:
# Lista de las variables categóricas
categorical_vars = data_train.select_dtypes(include=['category', 'object']).columns
# Imputar las variables categóricas con la moda
for data in data_train, data_test:
for var in categorical_vars:
mode_value = data[var].mode()[0]
data[var].fillna(mode_value, inplace=True)Verificación:
# Cantidad de valores faltantes por variable
missing_counts = data_test.isnull().sum()
# Frecuencia de valores faltantes por variable
missing_freq = data_test.isnull().mean() * 100
# Filtrar solo las columnas con valores faltantes
missing_data = pd.DataFrame({'Missing Count': missing_counts, 'Missing Frequency (%)': missing_freq})
missing_data = missing_data[missing_data['Missing Count'] > 0].sort_values(by='Missing Count', ascending=False)
print(missing_data)Empty DataFrame
Columns: [Missing Count, Missing Frequency (%)]
Index: []Todas las variables numéricas y categóricas se encuentran imputadas.
Restricciones del rango de datos
Todas las variables numéricas representan ingresos, cantidades o porcentajes, por ende no pueden tomar valores negativos. Realizamos un análisis descriptivo de las variables numéricas para verificar esto:
# Filtrando sólo columnas numéricas
numeric_data = data_train.select_dtypes(include=['float64', 'int64'])
# Obteniendo descripción numérica
description = numeric_data.describe()
print(description) NC_DISTR12 TOTGEST6 TOTGEST12 DIAS_ACT \
count 757388.000000 757388.000000 757388.000000 757388.000000
mean 0.549909 7.332889 9.077924 307.156523
std 0.223876 5.693403 7.631586 494.100978
min 0.005435 1.000000 1.000000 -20.000000
25% 0.421053 4.000000 4.000000 58.000000
50% 0.549908 6.000000 7.000000 133.000000
75% 0.600000 9.000000 11.000000 304.000000
max 1.000000 188.000000 212.000000 43129.000000
DIAS_BEST6 DIAS_ULT6 DIAS_BEST12 DIAS_ULT12 \
count 757388.000000 757388.000000 757388.000000 757388.000000
mean 51.923335 35.098432 63.945744 42.443416
std 45.829328 39.418088 66.230946 55.489267
min 0.000000 0.000000 0.000000 0.000000
25% 22.000000 13.000000 22.000000 13.000000
50% 40.000000 22.000000 44.000000 23.000000
75% 59.000000 41.000000 74.000000 46.000000
max 240.000000 240.000000 394.000000 393.000000
CNE_CTD12 CNE_CTD6 ... RECENCIA_APP NT_CTD12 \
count 757388.000000 757388.000000 ... 757388.000000 757388.000000
mean 2.261546 2.105890 ... 24.459388 1.008817
std 1.474584 1.144167 ... 73.926115 0.106256
min 1.000000 1.000000 ... 0.000000 1.000000
25% 2.000000 2.000000 ... 16.000000 1.000000
50% 2.000000 2.000000 ... 16.000000 1.000000
75% 2.000000 2.000000 ... 16.000000 1.000000
max 34.000000 25.000000 ... 2220.000000 6.000000
NT_DISTR12 NT_DIAS12 NT_CTD6 NT_DISTR6 \
count 757388.000000 757388.000000 757388.000000 757388.000000
mean 0.079309 168.978365 1.004601 0.101750
std 0.032672 22.894200 0.074847 0.030434
min 0.006579 0.000000 1.000000 0.007874
25% 0.076923 168.977995 1.000000 0.100000
50% 0.076923 168.977995 1.000000 0.100000
75% 0.076923 168.977995 1.000000 0.100000
max 1.000000 393.000000 6.000000 1.000000
NT_DIAS6 INGRESO_NETO_VIGENTE INGRESO_BRUTO TARGET
count 757388.000000 7.573880e+05 7.573880e+05 757388.000000
mean 121.342835 3.766212e+03 4.849734e+03 0.650113
std 11.710698 3.971474e+03 5.806693e+03 0.476934
min 0.000000 3.690000e+02 4.140000e+02 0.000000
25% 121.342591 1.636000e+03 1.838000e+03 0.000000
50% 121.342591 2.760000e+03 3.285000e+03 1.000000
75% 121.342591 4.701000e+03 5.950000e+03 1.000000
max 212.000000 1.639737e+06 2.411377e+06 1.000000
[8 rows x 28 columns]La variable DIAS_ACT que describe la cantidad de días que ha sido activo el teléfono, es como una recencia, no debe tomar valores negativos. Reemplazamos los valores negativos por el valor mínimo que es 0:
for data in data_train, data_test:
data.loc[data['DIAS_ACT'] < 0, 'DIAS_ACT'] = 0Detección y tratamiento de valores atípicos
Los valores atípicos suelen ser valores que se alejan significativamente de la media o mediana. Una técnica común es utilizar el rango intercuartílico (IQR). Un valor podría ser considerado atípico si se encuentra a más de 1.5 veces el IQR por debajo del primer cuartil o por encima del tercer cuartil.
numeric_vars = data_train.select_dtypes(include=['int64', 'float64']).columns
outlier_columns = []
for col in numeric_vars:
Q1 = data_train[col].quantile(0.25)
Q3 = data_train[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
if data_train[(data_train[col] < lower_bound) | (data_train[col] > upper_bound)].shape[0] > 0:
outlier_columns.append(col)
print(outlier_columns)['NC_DISTR12', 'TOTGEST6', 'TOTGEST12', 'DIAS_ACT', 'DIAS_BEST6', 'DIAS_ULT6', 'DIAS_BEST12', 'DIAS_ULT12', 'CNE_CTD12', 'CNE_CTD6', 'CNE_DIAS6', 'CNE_DISTR6', 'CNE_DISTR12', 'CNE_DIAS12', 'NC_CTD12', 'NC_DIAS6', 'NC_DIAS12', 'NC_CTD6', 'RECENCIA_APP', 'NT_CTD12', 'NT_DISTR12', 'NT_DIAS12', 'NT_CTD6', 'NT_DISTR6', 'NT_DIAS6', 'INGRESO_NETO_VIGENTE', 'INGRESO_BRUTO']Realizamos una descripción más detallada de las variables numéricas que presentan valores atípicos:
| Variable | Descripción | Descripción Detallada |
|---|---|---|
| TOTGEST6 | Cuantas gestiones se le realizo a la persona últimos 6 meses | Número total de gestiones o acciones realizadas con el cliente en el periodo de los últimos 6 meses. |
| TOTGEST12 | Cuantas gestiones se le realizo a la persona últimos 12 meses | Número total de gestiones o acciones realizadas con el cliente en el periodo de los últimos 12 meses. |
| DIAS_ACT | Cuanto ha sido la cantidad de día que ha sido activo el telefono, es como una resencia | Número de días en que el teléfono del cliente ha estado activo; es una medida de cuán reciente ha estado en uso. |
| DIAS_BEST6 | Dias del mejor resultado de los útimo 6 meses | Días transcurridos desde el mejor resultado o feedback obtenido durante los últimos 6 meses. |
| DIAS_ULT6 | Dias del de último feedback de los útimo 6 meses | Días transcurridos desde el último feedback registrado durante los últimos 6 meses. |
| DIAS_BEST12 | Dias del mejor resultado de los útimo 12 meses | Días transcurridos desde el mejor resultado o feedback obtenido durante los últimos 12 meses. |
| DIAS_ULT12 | Dias del de último feedback de los útimo 12 meses | Días transcurridos desde el último feedback registrado durante los últimos 12 meses. |
| CNE_CTD12 | Cantidad de contactos no efectivos útimos 12 meses | Número total de intentos de contacto durante los últimos 12 meses que no resultaron en un contacto efectivo. |
| CNE_CTD6 | Cantidad de contactos no efectivos útimos 6 meses | Número total de intentos de contacto durante los últimos 6 meses que no resultaron en un contacto efectivo. |
| CNE_DIAS6 | Días de contactos no efectivos útimos 6 meses | Días en que hubo intentos de contacto durante los últimos 6 meses que no resultaron en un contacto efectivo. |
| CNE_DISTR6 | Distribución del contacto no efectivo los últimos 6 meses | Proporción o porcentaje de intentos de contacto en los últimos 6 meses que no resultaron en un contacto efectivo. |
| CNE_DISTR12 | Distribución del contacto no efectivo los últimos 12 meses | Proporción o porcentaje de intentos de contacto en los últimos 12 meses que no resultaron en un contacto efectivo. |
| CNE_DIAS12 | Días de contactos no efectivos útimos 12 meses | Días en que hubo intentos de contacto durante los últimos 12 meses que no resultaron en un contacto efectivo. |
| NC_CTD12 | Cantidad de no contacto en los últimos 12 meses | Número total de ocasiones en las que no se pudo establecer contacto con el cliente en los últimos 12 meses. |
| NC_DIAS6 | Días de no contacto en los último 6 meses | Días específicos en los que no se pudo establecer contacto con el cliente durante los últimos 6 meses. |
| NC_DIAS12 | Días de no contacto en los último 12 meses | Días específicos en los que no se pudo establecer contacto con el cliente durante los últimos 12 meses. |
| NC_CTD6 | Cantidad de no contacto en los últimos 6 meses | Número total de ocasiones en las que no se pudo establecer contacto con el cliente en los últimos 6 meses. |
| NC_DISTR12 | % Distribución del no contacto en los 12 último meses | Proporción o porcentaje de veces que no se pudo establecer contacto con el cliente en los últimos 12 meses. |
| INGRESO_NETO_VIGENTE | Ingreso neto | Ingreso que el cliente recibe después de deducir impuestos y otros gastos. |
| INGRESO_BRUTO | Ingreso bruto | Ingreso total que el cliente recibe sin tener en cuenta deducciones o gastos. |
No se debe considerar presencia de valores atípicos en las variables que describen porcentajes. Estas variables son: CNE_DISTR6, CNE_DISTR12, y NC_DISTR12.
outlier_columns = [col for col in outlier_columns if col not in ['CNE_DISTR6', 'CNE_DISTR12', 'NC_DISTR12']]
print(outlier_columns)['TOTGEST6', 'TOTGEST12', 'DIAS_ACT', 'DIAS_BEST6', 'DIAS_ULT6', 'DIAS_BEST12', 'DIAS_ULT12', 'CNE_CTD12', 'CNE_CTD6', 'CNE_DIAS6', 'CNE_DIAS12', 'NC_CTD12', 'NC_DIAS6', 'NC_DIAS12', 'NC_CTD6', 'RECENCIA_APP', 'NT_CTD12', 'NT_DISTR12', 'NT_DIAS12', 'NT_CTD6', 'NT_DISTR6', 'NT_DIAS6', 'INGRESO_NETO_VIGENTE', 'INGRESO_BRUTO']Mostramos histogramas para visualizar la presencia de valores atípicos en cada una de las variables numéricas que presentan valores atípicos:
# Definir el número de subplots en función de la cantidad de columnas con outliers
n = len(outlier_columns)
fig, axes = plt.subplots(n, 1, figsize=(10, 5*n))
# Si solo hay una variable con outliers, "axes" no será una lista, así que lo convertimos en una lista
if n == 1:
axes = [axes]
for i, col in enumerate(outlier_columns):
data_train[col].hist(ax=axes[i], bins=50, edgecolor='black')
axes[i].set_title(f'Histograma de {col}')
axes[i].set_xlabel(col)
axes[i].set_ylabel('Frecuencia')
# Líneas verticales para mostrar Q1, Q3 y posibles valores atípicos usando IQR
Q1 = data_train[col].quantile(0.25)
Q3 = data_train[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
axes[i].axvline(x=Q1, color='r', linestyle='--', label='Q1')
axes[i].axvline(x=Q3, color='g', linestyle='--', label='Q3')
axes[i].axvline(x=lower_bound, color='b', linestyle='--', label='Lower Bound')
axes[i].axvline(x=upper_bound, color='y', linestyle='--', label='Upper Bound')
axes[i].legend()
plt.tight_layout()
plt.show()
Realizamos un análisis descriptivo de estas variables:
Estos histogramas muestran asimetría hacia la derecha. Se procede a aplicar la transformación logarítmica para reducir la asimetría:
for data in data_train, data_test:
for column in outlier_columns:
if data[column].min() == 0:
data[column] = data[column] + 1
data[column] = np.log(data[column])Verificamos que la transformación logarítmica ha reducido la asimetría:
# Definir el número de subplots en función de la cantidad de columnas con outliers
n = len(outlier_columns)
fig, axes = plt.subplots(n, 1, figsize=(10, 5*n))
# Si solo hay una variable con outliers, "axes" no será una lista, así que lo convertimos en una lista
if n == 1:
axes = [axes]
for i, col in enumerate(outlier_columns):
data_train[col].hist(ax=axes[i], bins=50, edgecolor='black')
axes[i].set_title(f'Histograma de {col}')
axes[i].set_xlabel(col)
axes[i].set_ylabel('Frecuencia')
# Líneas verticales para mostrar Q1, Q3 y posibles valores atípicos usando IQR
Q1 = data_train[col].quantile(0.25)
Q3 = data_train[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
axes[i].axvline(x=Q1, color='r', linestyle='--', label='Q1')
axes[i].axvline(x=Q3, color='g', linestyle='--', label='Q3')
axes[i].axvline(x=lower_bound, color='b', linestyle='--', label='Lower Bound')
axes[i].axvline(x=upper_bound, color='y', linestyle='--', label='Upper Bound')
axes[i].legend()
plt.tight_layout()
plt.show()
Tratamiento de variables temporales
Se cuenta con una variable temporal (FEC_LLAMADA) que puede dividirse en año, mes, día, día de la semana.
for data in data_train, data_test:
data['YEAR'] = data['FEC_LLAMADA'].dt.year
data['MONTH'] = data['FEC_LLAMADA'].dt.month
data['WEEKDAY'] = data['FEC_LLAMADA'].dt.weekday # 0: Monday, 6: Sundaycomponents = ['YEAR', 'MONTH', 'WEEKDAY']
for data in data_train, data_test:
for component in components:
data[component] = data[component].astype('category')Evaluemos los valores únicos que toman estas nuevas variables:
# Evaluar valores únicos para cada componente
unique_years = data_train['YEAR'].unique()
unique_months = data_train['MONTH'].unique()
unique_weekdays = data_train['WEEKDAY'].unique()
print(f"Valores únicos para AÑO: {sorted(unique_years)}")
print(f"Valores únicos para MES: {sorted(unique_months)}")
print(f"Valores únicos para DÍA DE LA SEMANA: {sorted(unique_weekdays)}")Valores únicos para AÑO: [2017, 2018]
Valores únicos para MES: [2, 7, 8, 9, 10, 11]
Valores únicos para DÍA DE LA SEMANA: [0, 1, 2, 3, 4, 5, 6]# Evaluar valores únicos para cada componente
unique_years = data_test['YEAR'].unique()
unique_months = data_test['MONTH'].unique()
unique_weekdays = data_test['WEEKDAY'].unique()
print(f"Valores únicos para AÑO: {sorted(unique_years)}")
print(f"Valores únicos para MES: {sorted(unique_months)}")
print(f"Valores únicos para DÍA DE LA SEMANA: {sorted(unique_weekdays)}")Valores únicos para AÑO: [2017]
Valores únicos para MES: [12]
Valores únicos para DÍA DE LA SEMANA: [0, 1, 2, 3, 4, 5]def get_frequencies(column_name):
abs_freq = data_train[column_name].value_counts()
rel_freq = data_train[column_name].value_counts(normalize=True) * 100
return pd.DataFrame({'Absoluta': abs_freq, 'Porcentual (%)': rel_freq})
# Frecuencias para cada componente
year_freq = get_frequencies('YEAR')
month_freq = get_frequencies('MONTH')
weekday_freq = get_frequencies('WEEKDAY')
print("Frecuencias para AÑO:\n", year_freq, "\n")
print("Frecuencias para MES:\n", month_freq, "\n")
print("Frecuencias para DÍA DE LA SEMANA:\n", weekday_freq)Frecuencias para AÑO:
Absoluta Porcentual (%)
YEAR
2017 555326 73.321204
2018 202062 26.678796
Frecuencias para MES:
Absoluta Porcentual (%)
MONTH
2 202062 26.678796
9 199027 26.278077
10 188666 24.910086
11 167596 22.128156
7 27 0.003565
8 10 0.001320
Frecuencias para DÍA DE LA SEMANA:
Absoluta Porcentual (%)
WEEKDAY
2 153475 20.263722
1 149397 19.725293
3 148969 19.668783
4 143120 18.896523
0 142070 18.757889
5 20356 2.687658
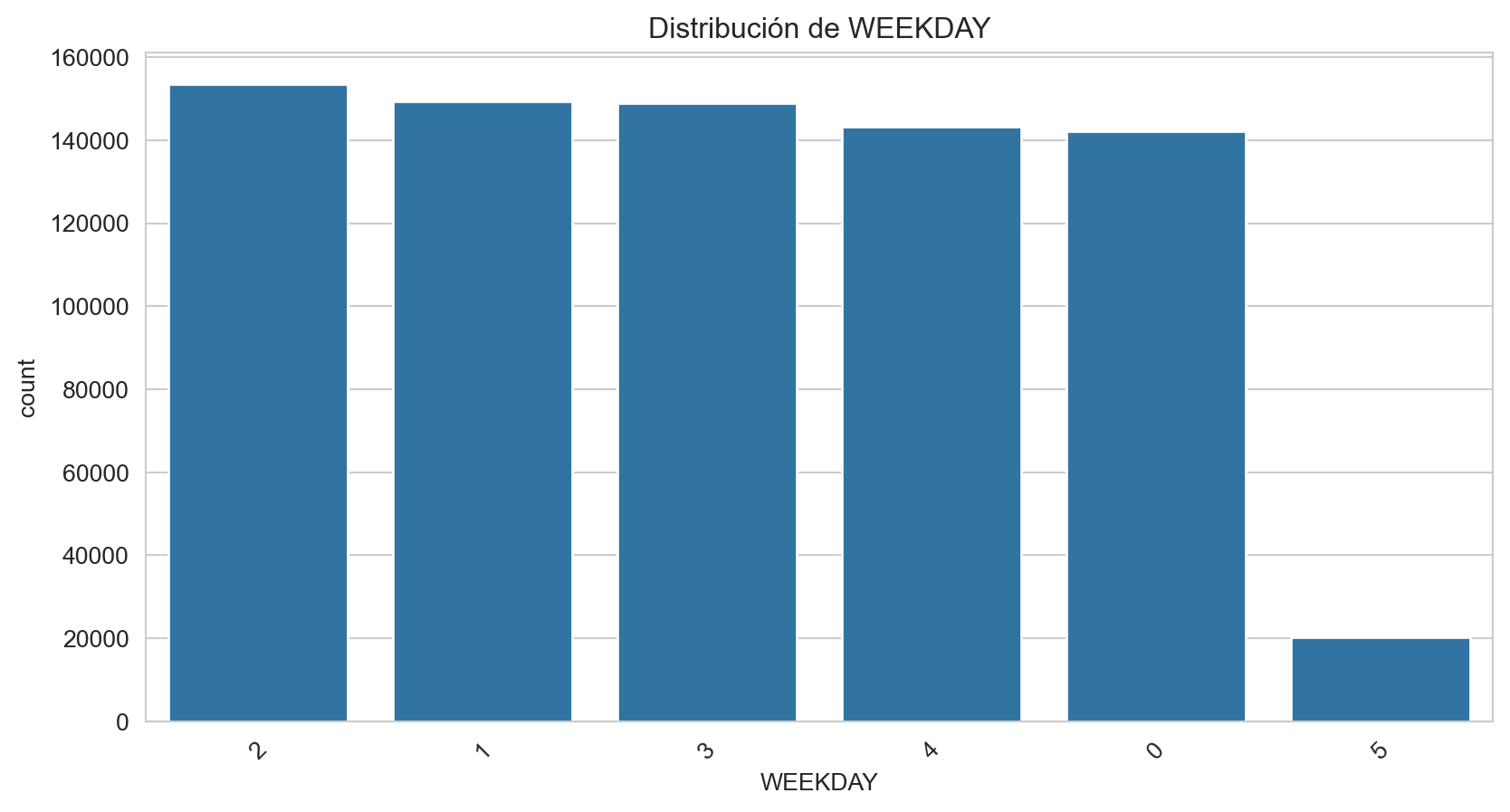
6 1 0.000132Dado que la variable FEC_LLAMADA presenta frecuencias porcentuales bajas para los valores 5 y 6, estos serán recodificados al valor de 5 que representará el fin de semana.
# Recodificar valores
for data in data_train, data_test:
data['WEEKDAY'] = data['WEEKDAY'].replace({6: 5})
# Comprobar las nuevas frecuencias
weekday_freq_updated = get_frequencies('WEEKDAY')
print("Frecuencias actualizadas para DÍA DE LA SEMANA:\n", weekday_freq_updated)Frecuencias actualizadas para DÍA DE LA SEMANA:
Absoluta Porcentual (%)
WEEKDAY
2 153475 20.263722
1 149397 19.725293
3 148969 19.668783
4 143120 18.896523
0 142070 18.757889
5 20357 2.687790
Frecuencias actualizadas para DÍA DE LA SEMANA:
Absoluta Porcentual (%)
WEEKDAY
2 153475 20.263722
1 149397 19.725293
3 148969 19.668783
4 143120 18.896523
0 142070 18.757889
5 20357 2.687790Análisis exploratorio de datos
Nuestra base de datos presenta las siguientes variables:
# Obtén una serie con los tipos de datos de cada columna
data_types_series = data_train.dtypes
# Construye una lista de listas con los nombres de las columnas y los tipos de datos
data_types_list = [[col, data_types_series[col]] for col in data_types_series.index]
# Construye la tabla Markdown como una string
markdown_table = "| Variable | Tipo de Dato Actual |\n|----------|--------------|\n"
for row in data_types_list:
markdown_table += f"| {row[0]} | {row[1]} |\n"
# Imprime la tabla Markdown
print(markdown_table)| Variable | Tipo de Dato Actual |
|----------|--------------|
| NUMPRIORIZACION | category |
| NC_DISTR12 | float64 |
| TOTGEST6 | float64 |
| TOTGEST12 | float64 |
| DIAS_ACT | float64 |
| FBK_ULT6 | category |
| FBK_ULT12 | category |
| FBK_BEST6 | category |
| DIAS_BEST6 | float64 |
| DIAS_ULT6 | float64 |
| FBK_BEST12 | category |
| DIAS_BEST12 | float64 |
| DIAS_ULT12 | float64 |
| CNE_CTD12 | float64 |
| CNE_CTD6 | float64 |
| CNE_DIAS6 | float64 |
| CNE_DISTR6 | float64 |
| CNE_DISTR12 | float64 |
| CNE_DIAS12 | float64 |
| NC_CTD12 | float64 |
| NC_DIAS6 | float64 |
| NC_DIAS12 | float64 |
| NC_CTD6 | float64 |
| RECENCIA_APP | float64 |
| COD_SALA | category |
| NT_CTD12 | float64 |
| NT_DISTR12 | float64 |
| NT_DIAS12 | float64 |
| FEC_LLAMADA | datetime64[ns] |
| NT_CTD6 | float64 |
| NT_DISTR6 | float64 |
| NT_DIAS6 | float64 |
| PROVINCIA | category |
| DEPARTAMENTO | category |
| INGRESO_NETO_VIGENTE | float64 |
| INGRESO_BRUTO | float64 |
| SEGMENTO | category |
| RANGO_INGRESOS | category |
| TARGET | int64 |
| YEAR | category |
| MONTH | category |
| WEEKDAY | category |
Análisis univariado
De variables numéricas
for column in data_train.select_dtypes(include=['float64', 'int64']).columns:
plt.figure(figsize=(10, 5))
# Histograma
plt.subplot(1, 2, 1)
sns.histplot(data_train[column], bins=50, kde=True)
plt.title(f'Distribución de {column}')
# Boxplot
plt.subplot(1, 2, 2)
sns.boxplot(y=data_train[column])
plt.title(f'Boxplot de {column}')
plt.tight_layout()
plt.show()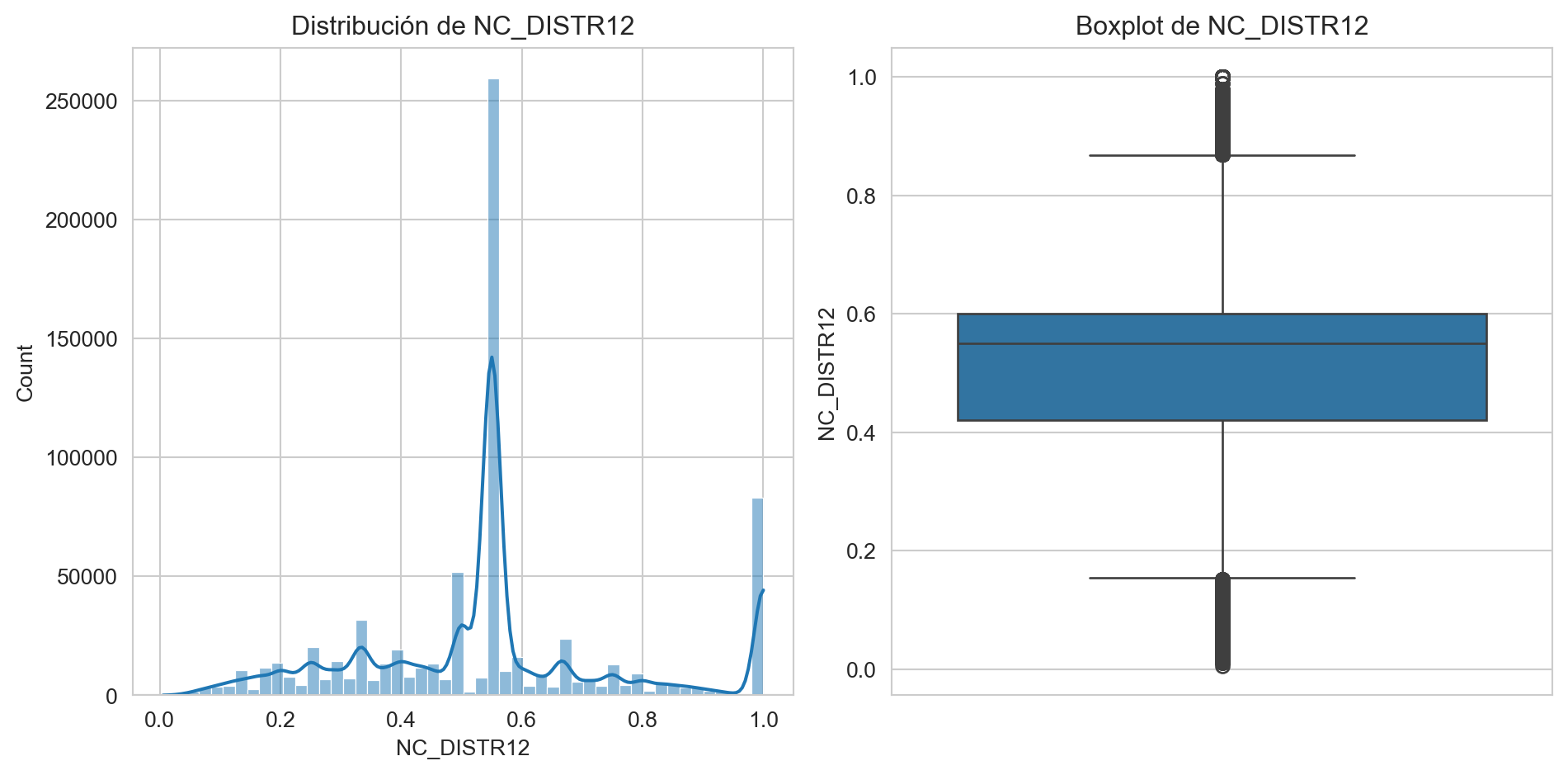
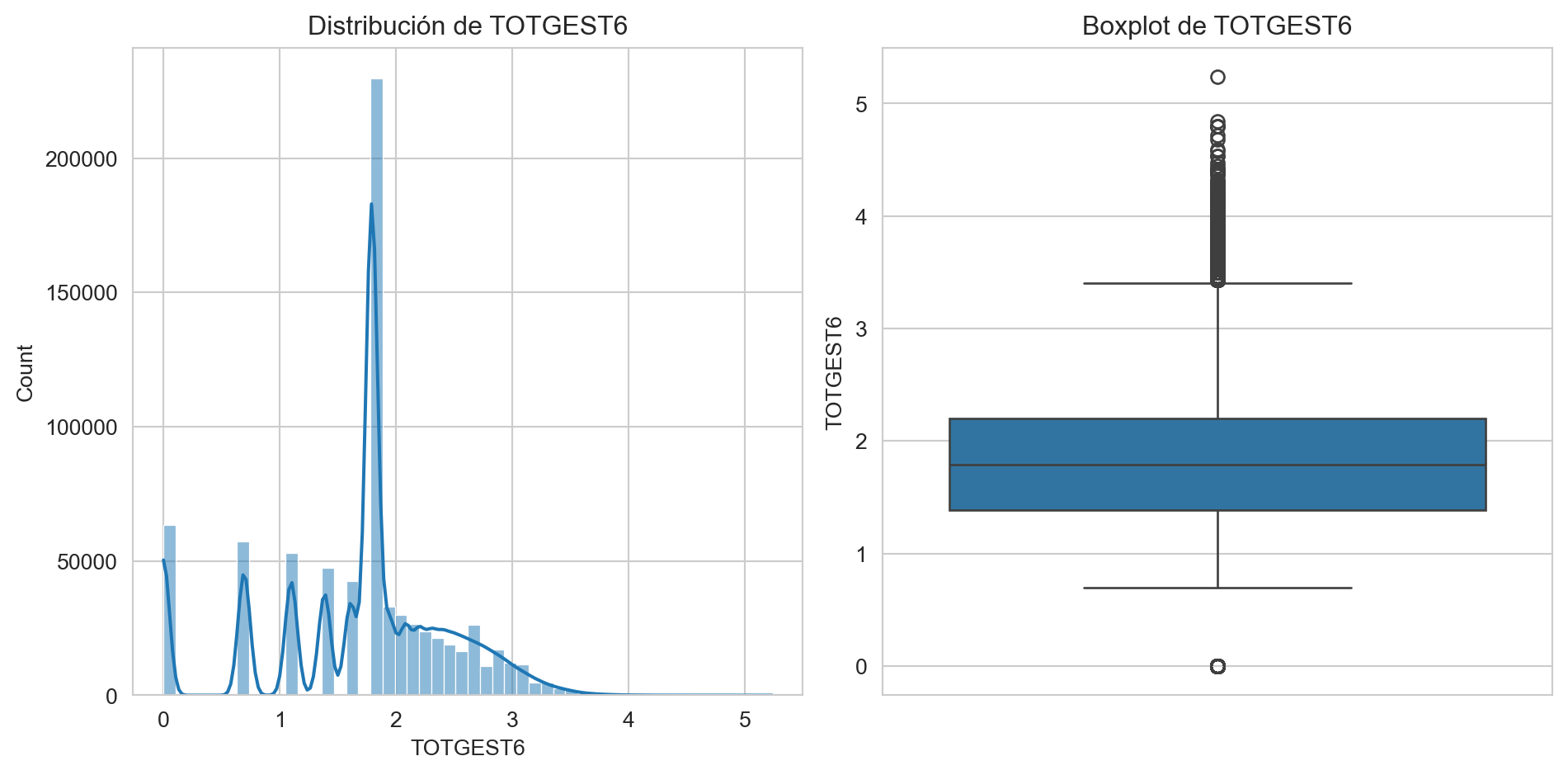
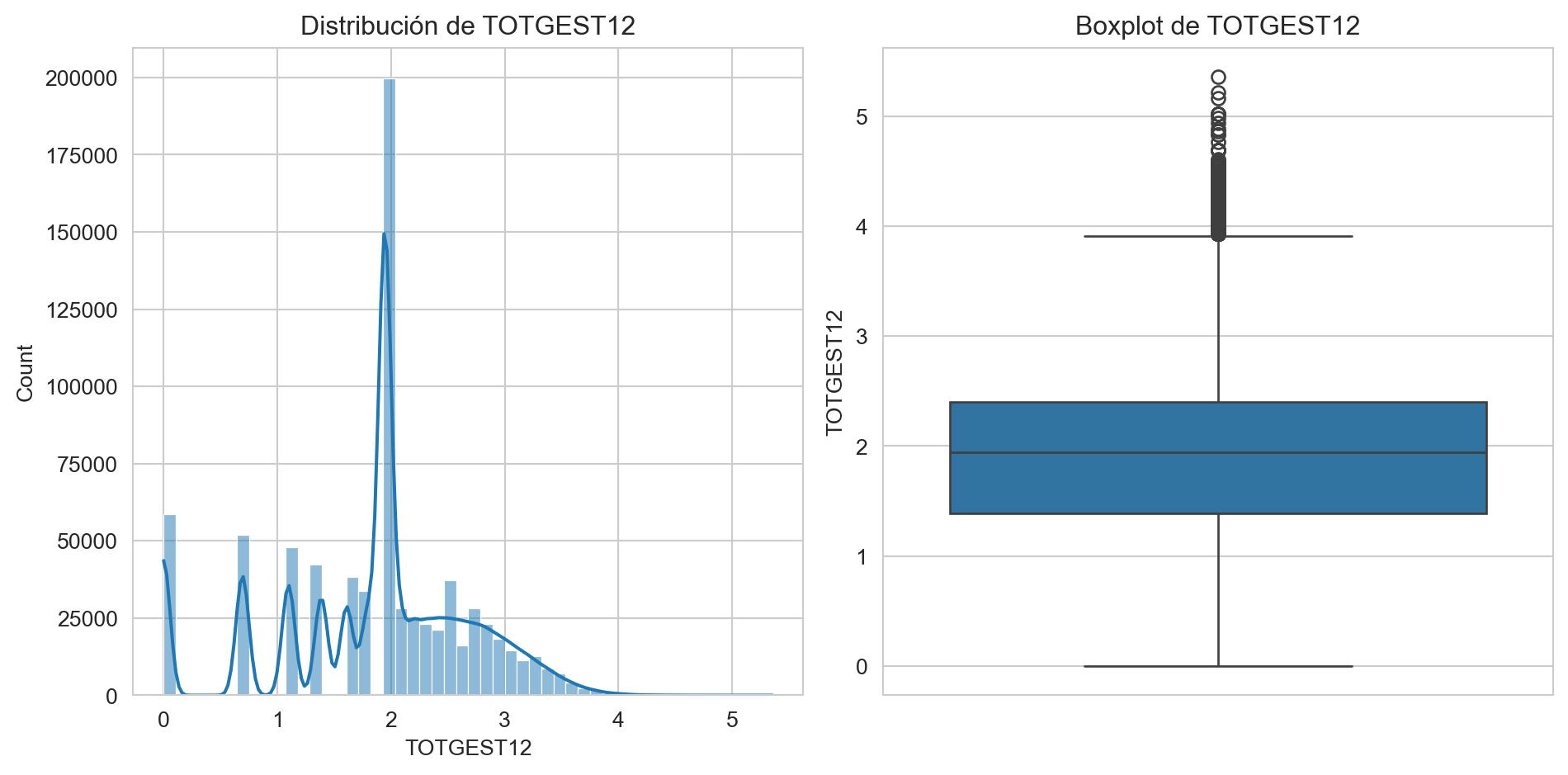
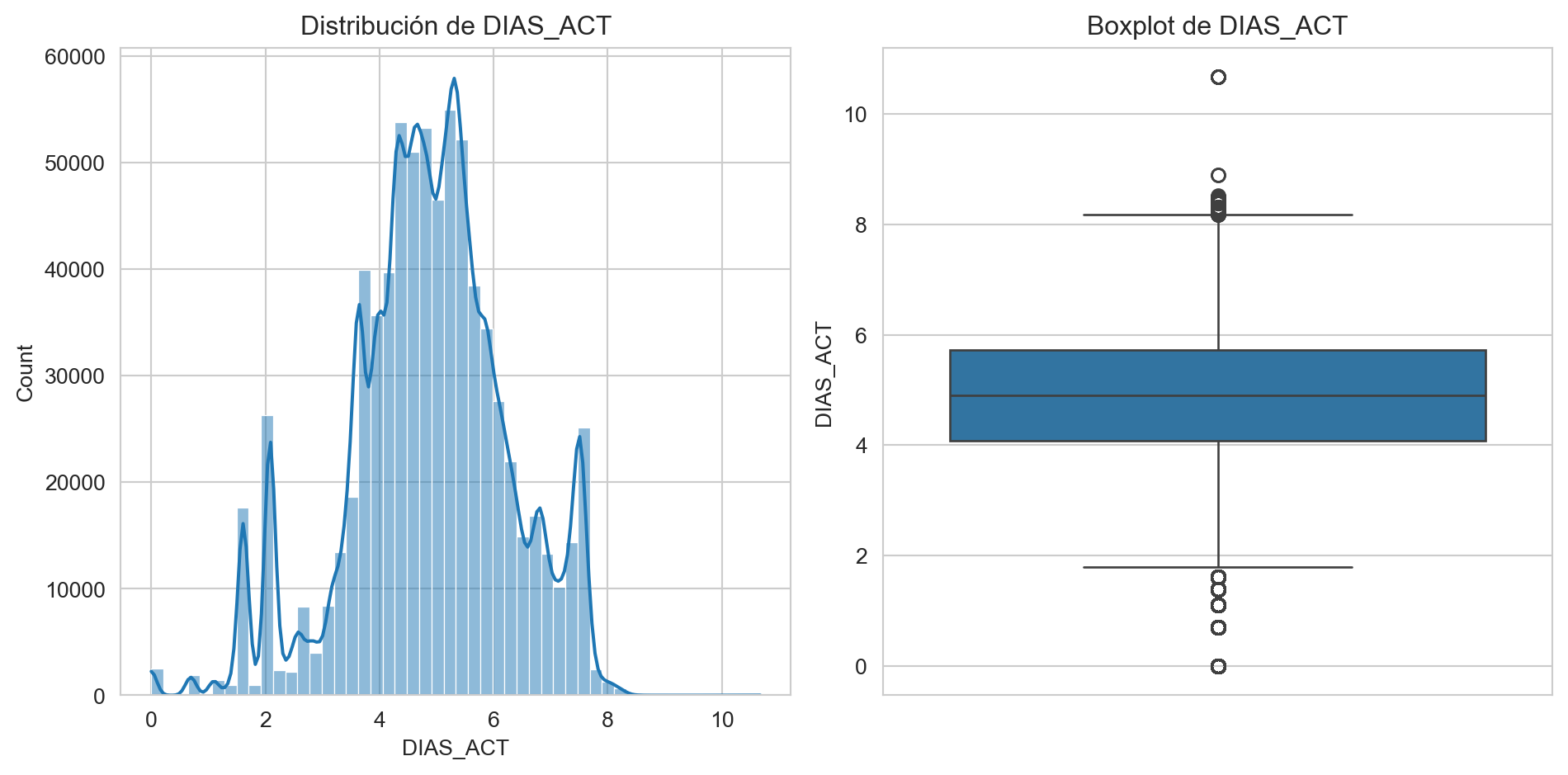
De variables categóricas
categorical_columns = data_train.select_dtypes(include=['category', 'object']).columns
for column in categorical_columns:
print(f"Frecuencias de {column}:")
print(data_train[column].value_counts(normalize=True) * 100)
print("\n")Frecuencias de NUMPRIORIZACION:
NUMPRIORIZACION
1 61.105404
2 18.662165
3 8.916302
4 4.824476
5 2.758560
6 1.625455
7 0.951956
8 0.567741
9 0.362298
10 0.225644
Name: proportion, dtype: float64
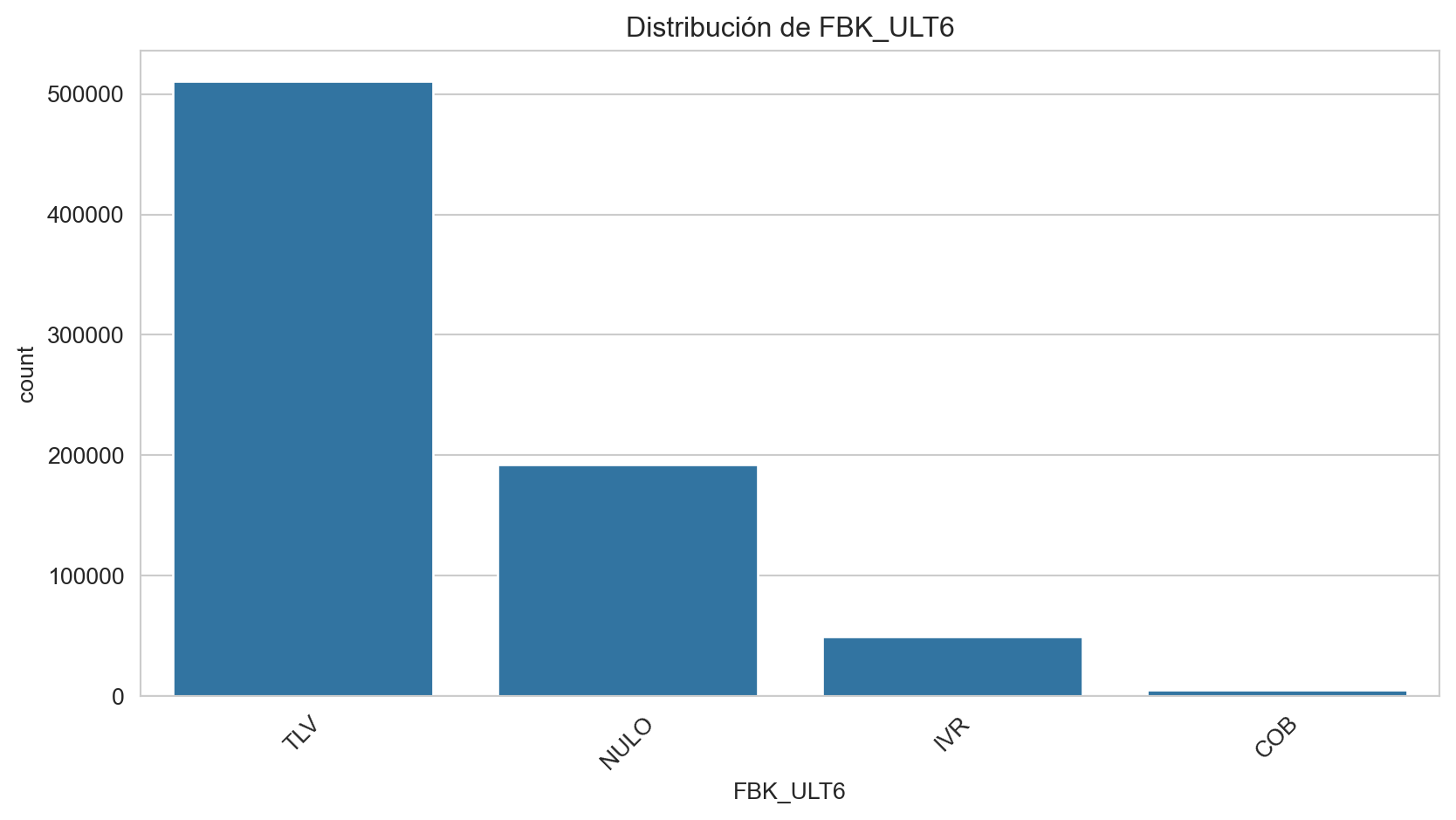
Frecuencias de FBK_ULT6:
FBK_ULT6
TLV 67.406138
NULO 25.343681
IVR 6.558461
COB 0.691719
Name: proportion, dtype: float64
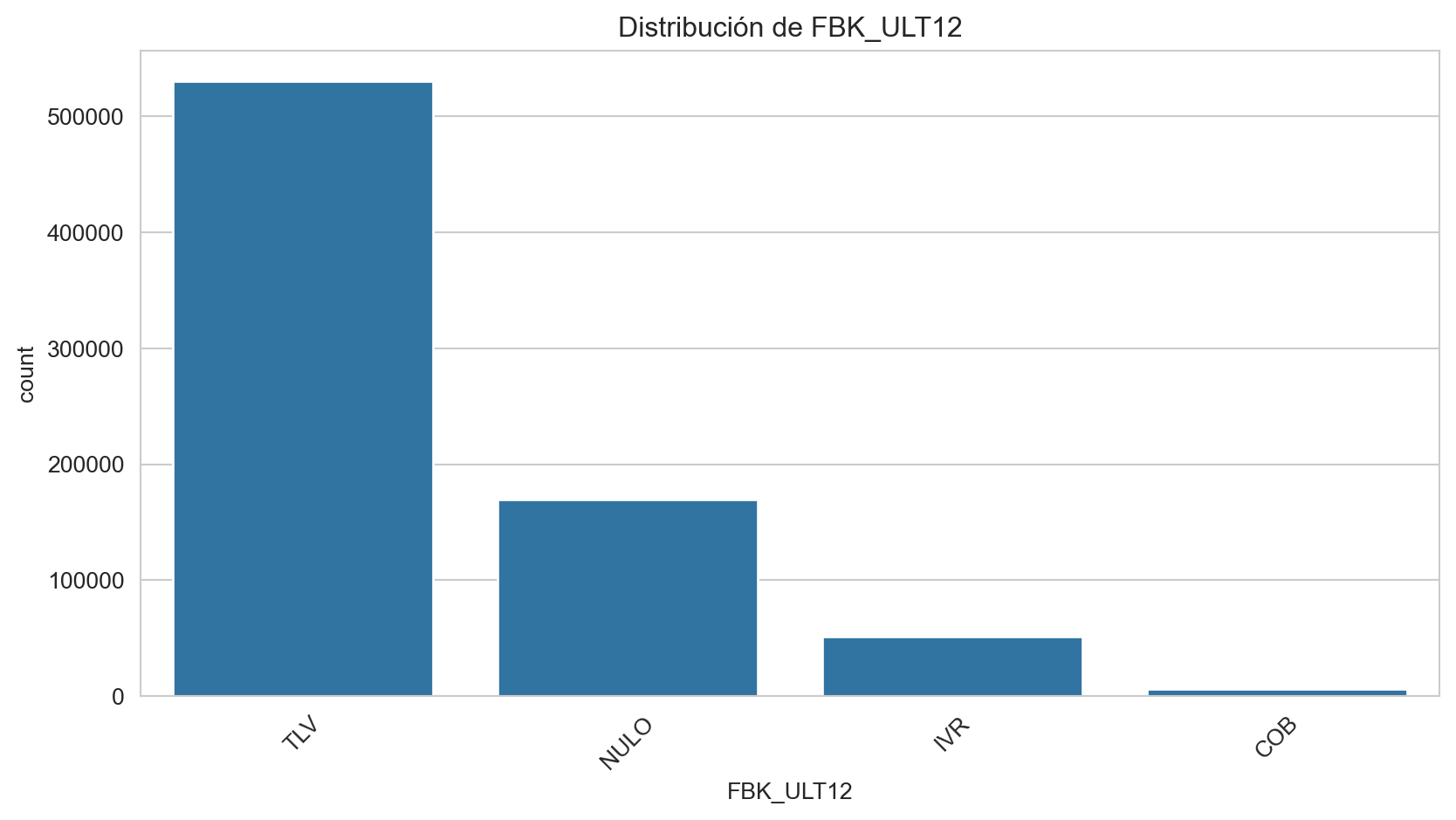
Frecuencias de FBK_ULT12:
FBK_ULT12
TLV 70.015633
NULO 22.380339
IVR 6.798233
COB 0.805796
Name: proportion, dtype: float64
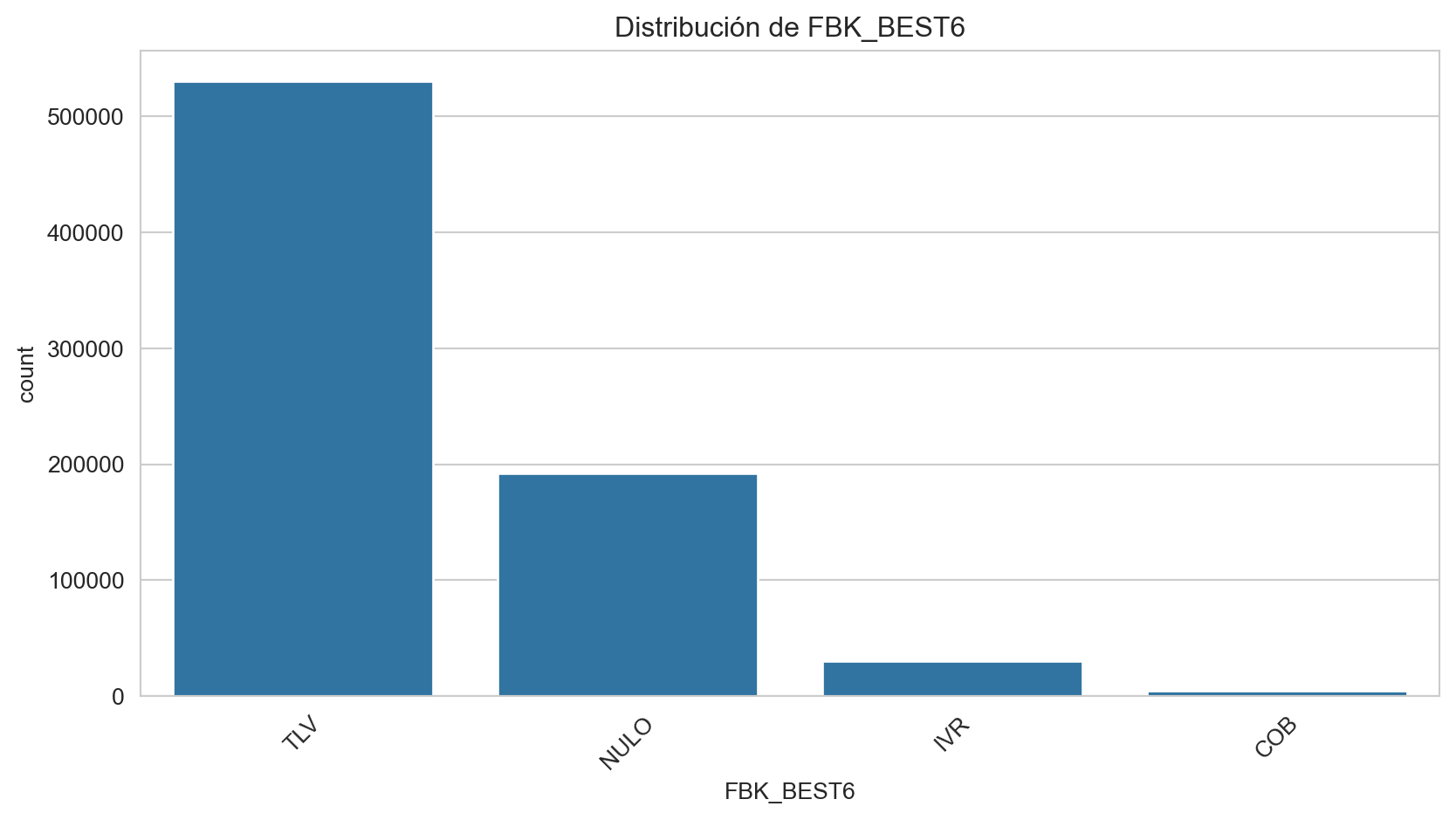
Frecuencias de FBK_BEST6:
FBK_BEST6
TLV 70.026195
NULO 25.343681
IVR 4.001516
COB 0.628608
Name: proportion, dtype: float64
Frecuencias de FBK_BEST12:
FBK_BEST12
TLV 73.348271
NULO 22.380339
IVR 3.600796
COB 0.670594
Name: proportion, dtype: float64
Frecuencias de COD_SALA:
COD_SALA
NC 31.636493
EC 18.479036
C 11.607129
PP 11.198223
CD 7.117620
PA 6.336779
CON 4.209863
IL 2.707067
UPG 2.256175
PRR 1.842517
2DA 1.770559
DIL 0.418808
BPE 0.414979
DEF 0.004093
TC 0.000660
Name: proportion, dtype: float64
Frecuencias de PROVINCIA:
PROVINCIA
LIMA 57.819110
AREQUIPA 5.092634
PROV. CONST. DEL CALLAO 3.522237
TRUJILLO 3.444866
INF. NO DISPONIBLE 3.291708
...
VICTOR FAJARDO 0.000528
GRAN CHIMU 0.000528
LAURICOCHA 0.000396
OCROS 0.000396
PURUS 0.000132
Name: proportion, Length: 192, dtype: float64
Frecuencias de DEPARTAMENTO:
DEPARTAMENTO
LIMA 59.507412
AREQUIPA 5.256091
LA LIBERTAD 3.853507
CALLAO 3.522237
LAMBAYEQUE 3.489493
INF. NO DISPONIBLE 3.291708
JUNIN 2.837647
PIURA 2.542686
ICA 2.485516
CUSCO 2.202438
ANCASH 1.370764
CAJAMARCA 1.369575
PUNO 1.359013
TACNA 1.168490
HUANUCO 0.935716
TUMBES 0.725652
SAN MARTIN 0.724464
LORETO 0.681025
UCAYALI 0.631909
MOQUEGUA 0.568269
AYACUCHO 0.410886
PASCO 0.384875
APURIMAC 0.202010
MADRE DE DIOS 0.178640
AMAZONAS 0.166625
HUANCAVELICA 0.133353
Name: proportion, dtype: float64
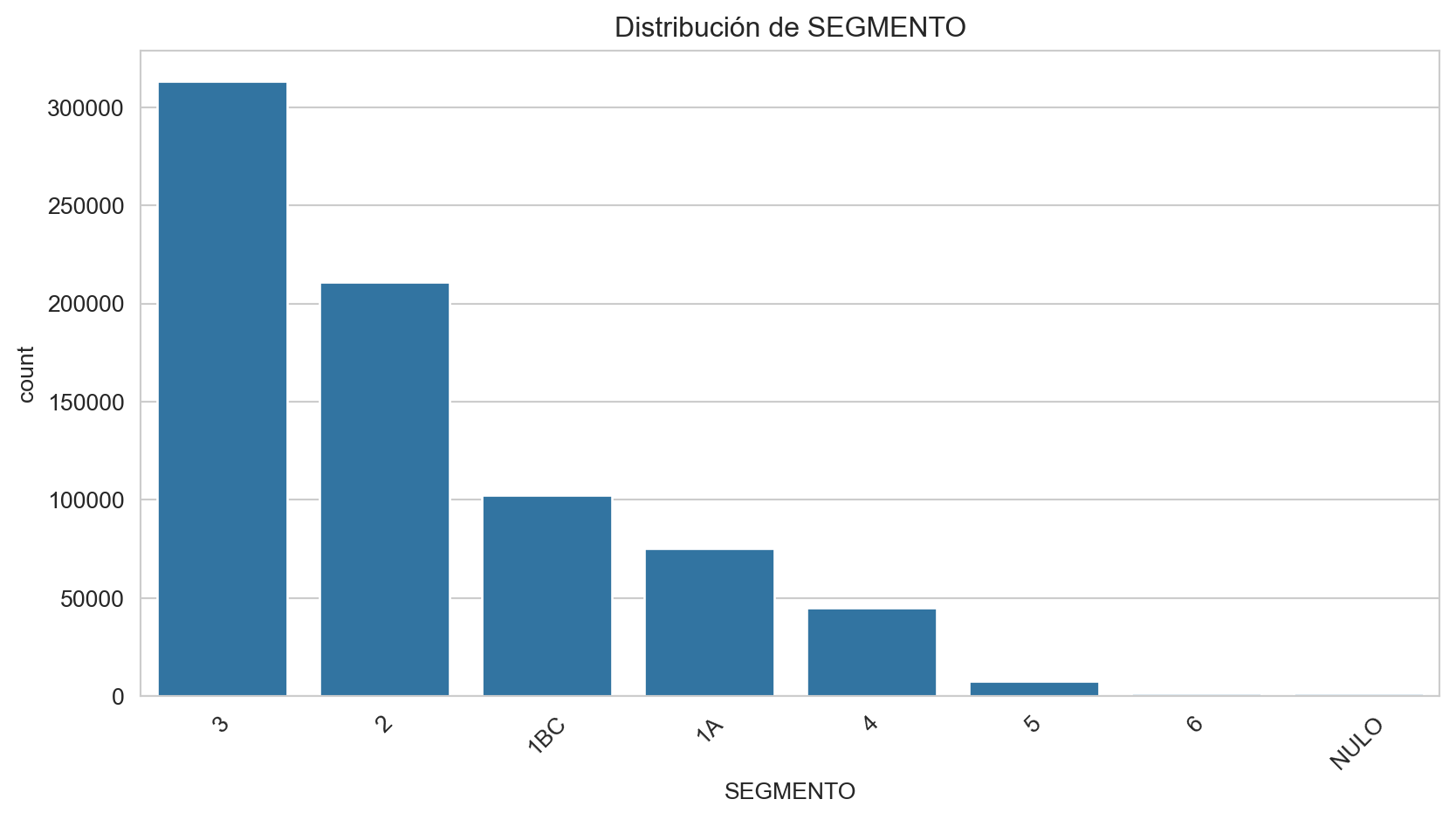
Frecuencias de SEGMENTO:
SEGMENTO
3 41.363476
2 27.868939
1BC 13.538635
1A 9.911697
4 5.945698
5 0.982984
6 0.202010
NULO 0.186562
Name: proportion, dtype: float64
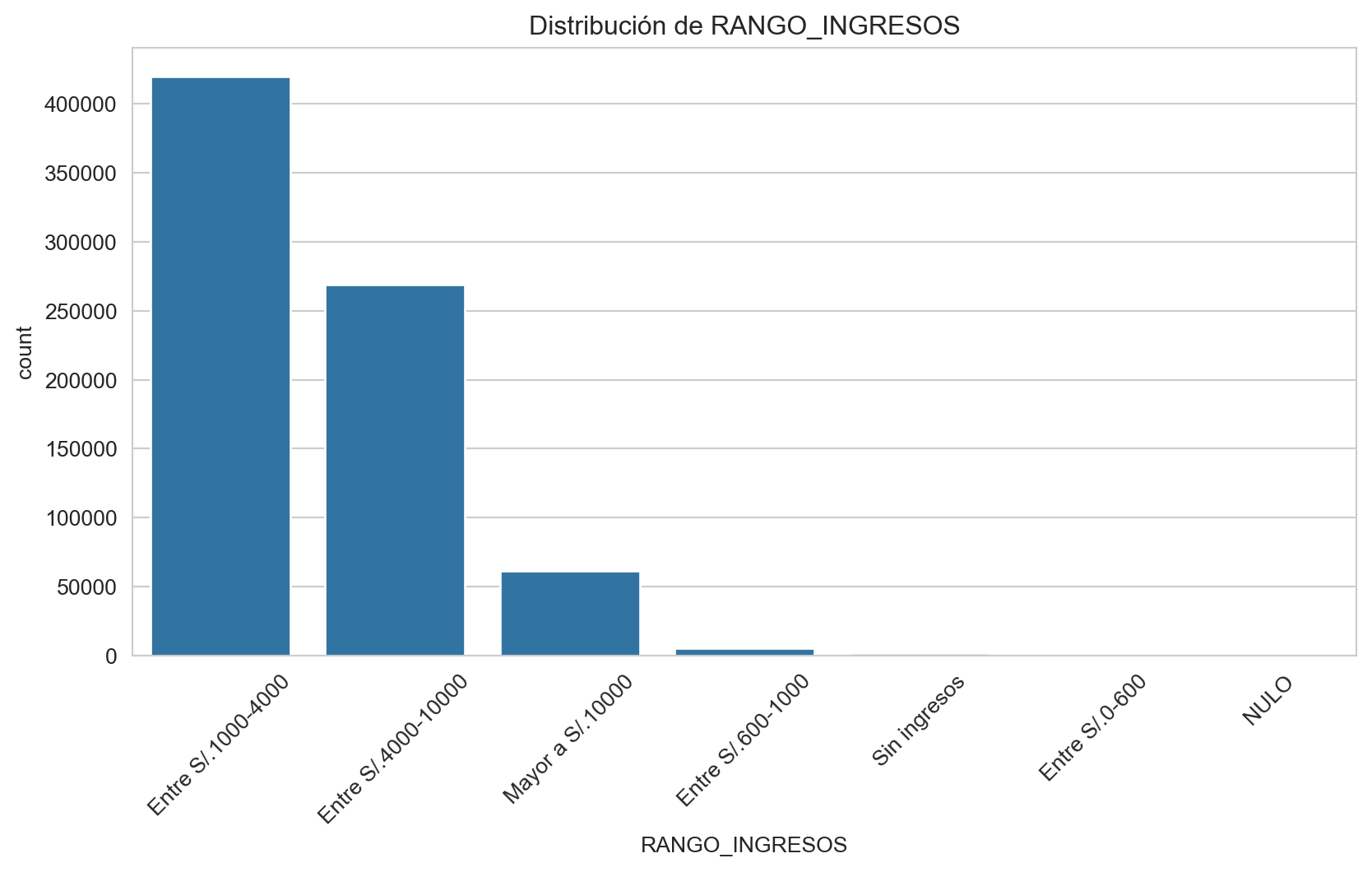
Frecuencias de RANGO_INGRESOS:
RANGO_INGRESOS
Entre S/.1000-4000 55.438164
Entre S/.4000-10000 35.496205
Mayor a S/.10000 8.140081
Entre S/.600-1000 0.709808
Sin ingresos 0.203859
Entre S/.0-600 0.011751
NULO 0.000132
Name: proportion, dtype: float64
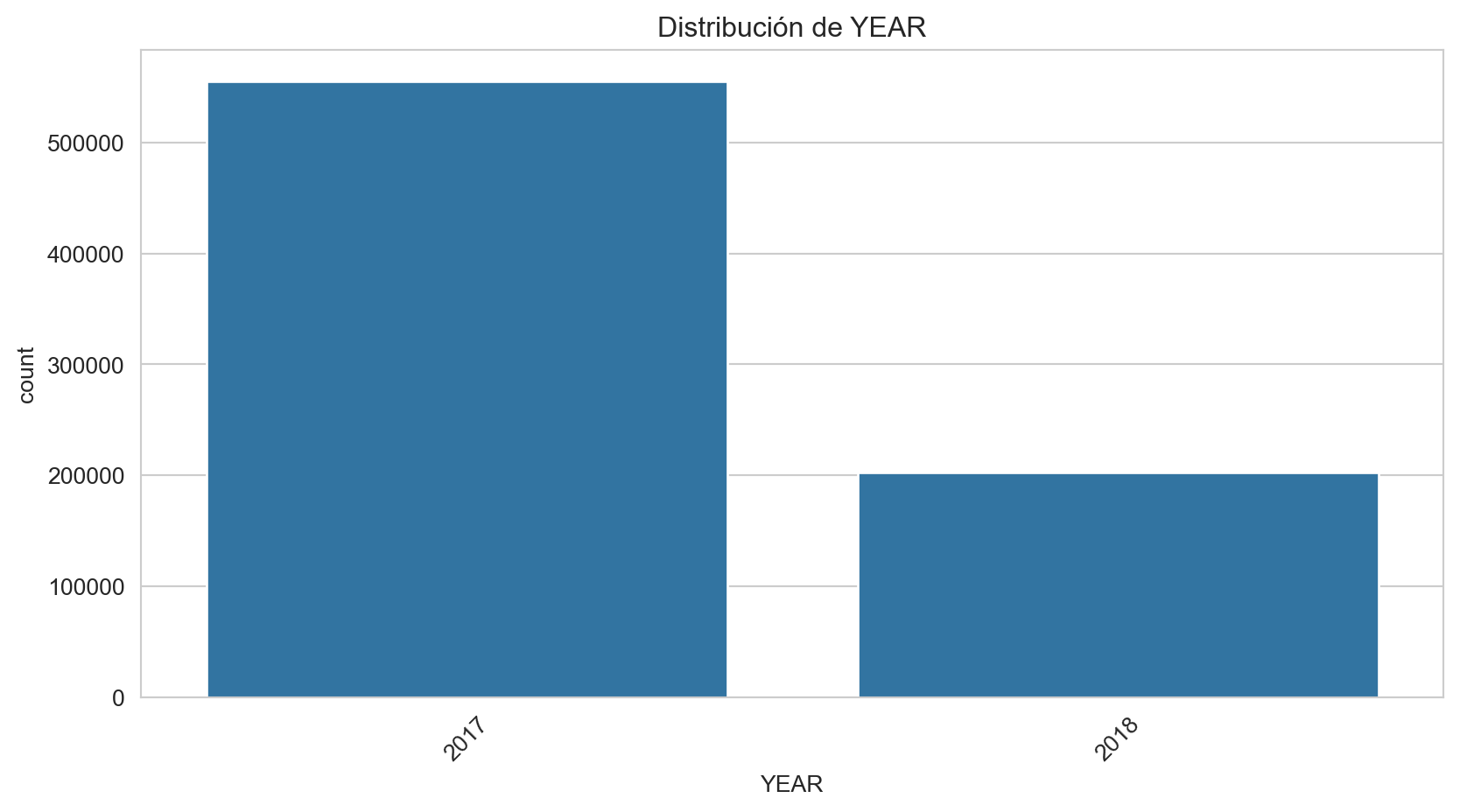
Frecuencias de YEAR:
YEAR
2017 73.321204
2018 26.678796
Name: proportion, dtype: float64
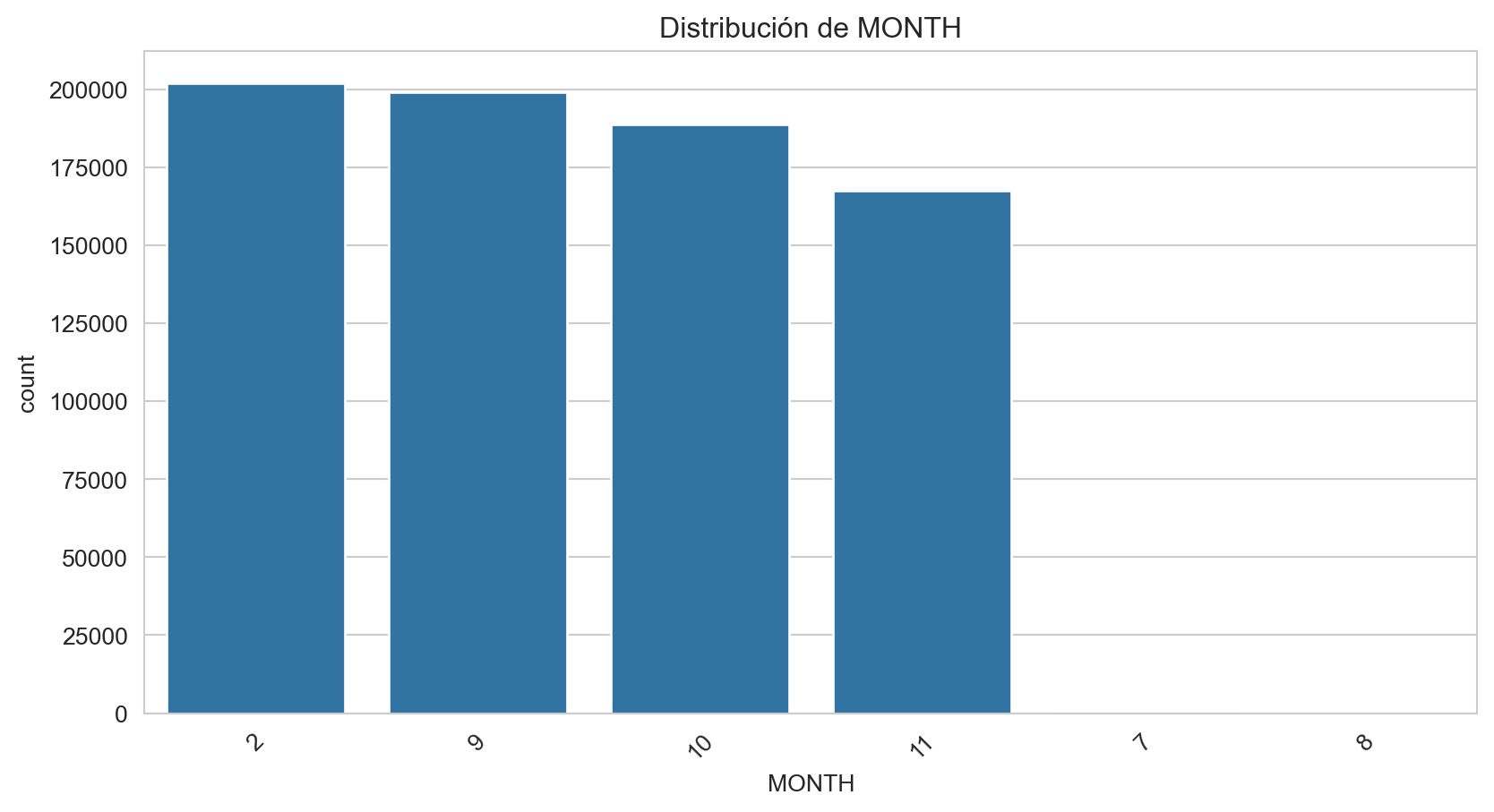
Frecuencias de MONTH:
MONTH
2 26.678796
9 26.278077
10 24.910086
11 22.128156
7 0.003565
8 0.001320
Name: proportion, dtype: float64
Frecuencias de WEEKDAY:
WEEKDAY
2 20.263722
1 19.725293
3 19.668783
4 18.896523
0 18.757889
5 2.687790
Name: proportion, dtype: float64
for column in categorical_columns:
plt.figure(figsize=(10, 5))
sns.countplot(data=data_train, x=column, order=data_train[column].value_counts().index)
plt.title(f'Distribución de {column}')
plt.xticks(rotation=45)
plt.show()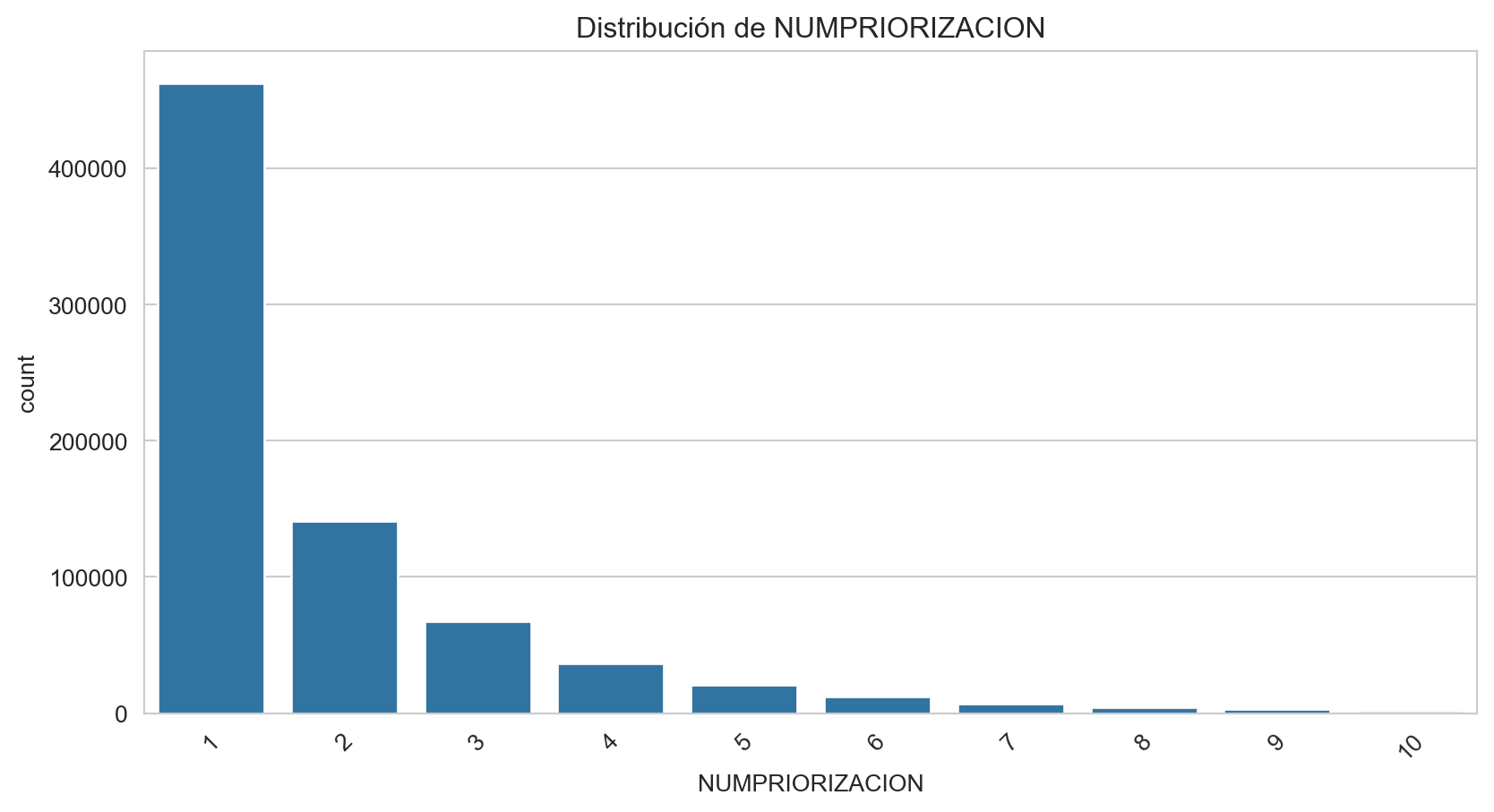
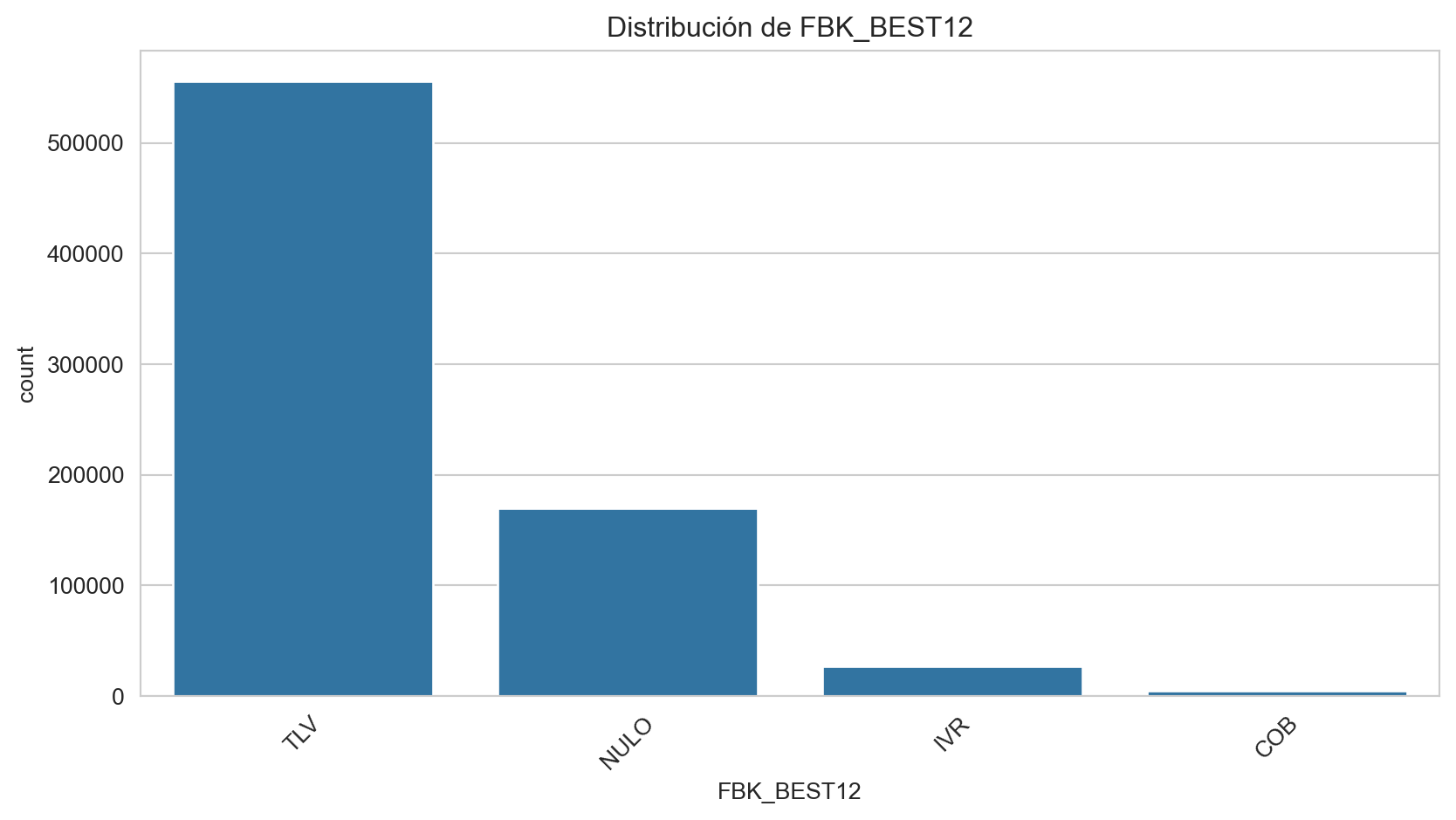
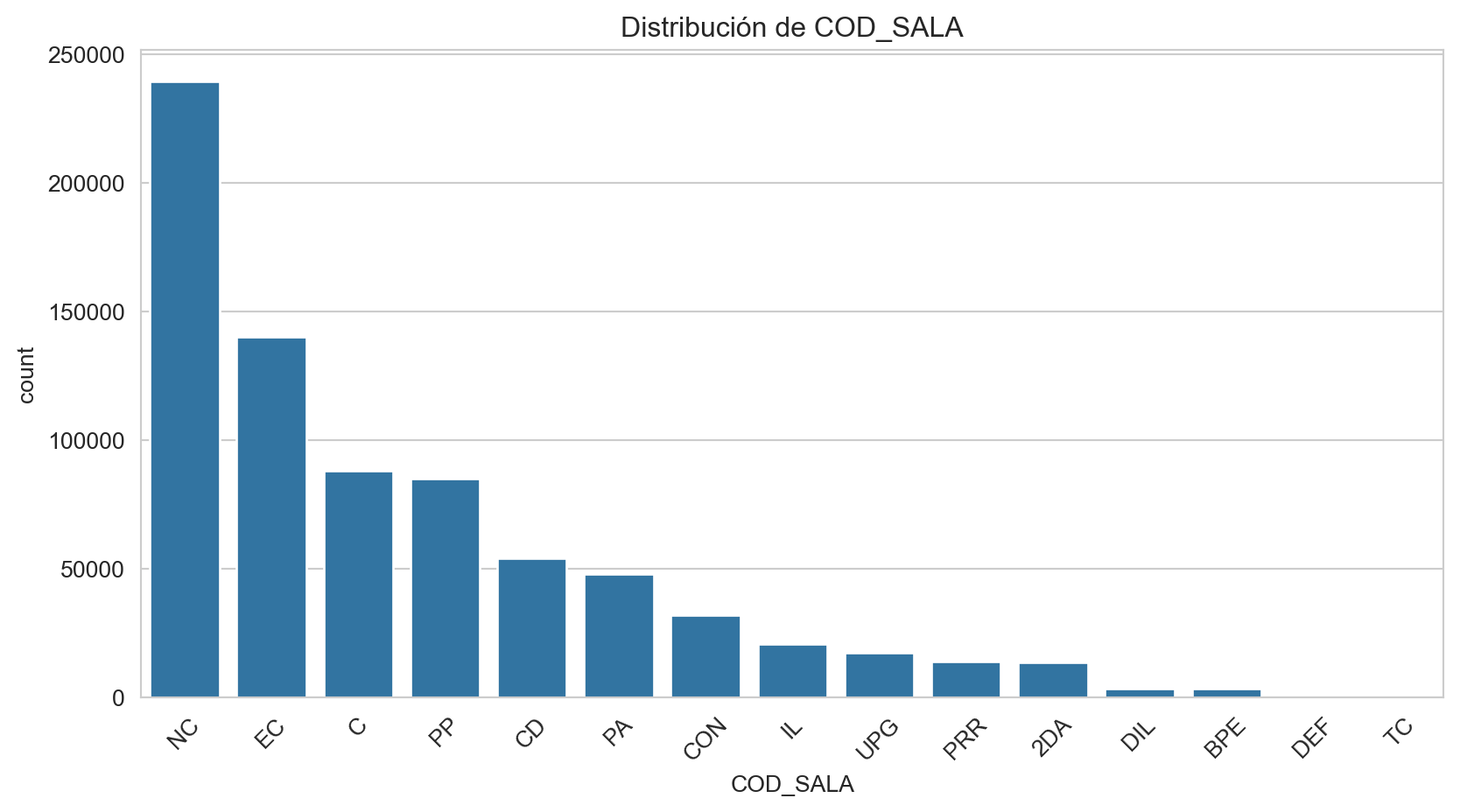
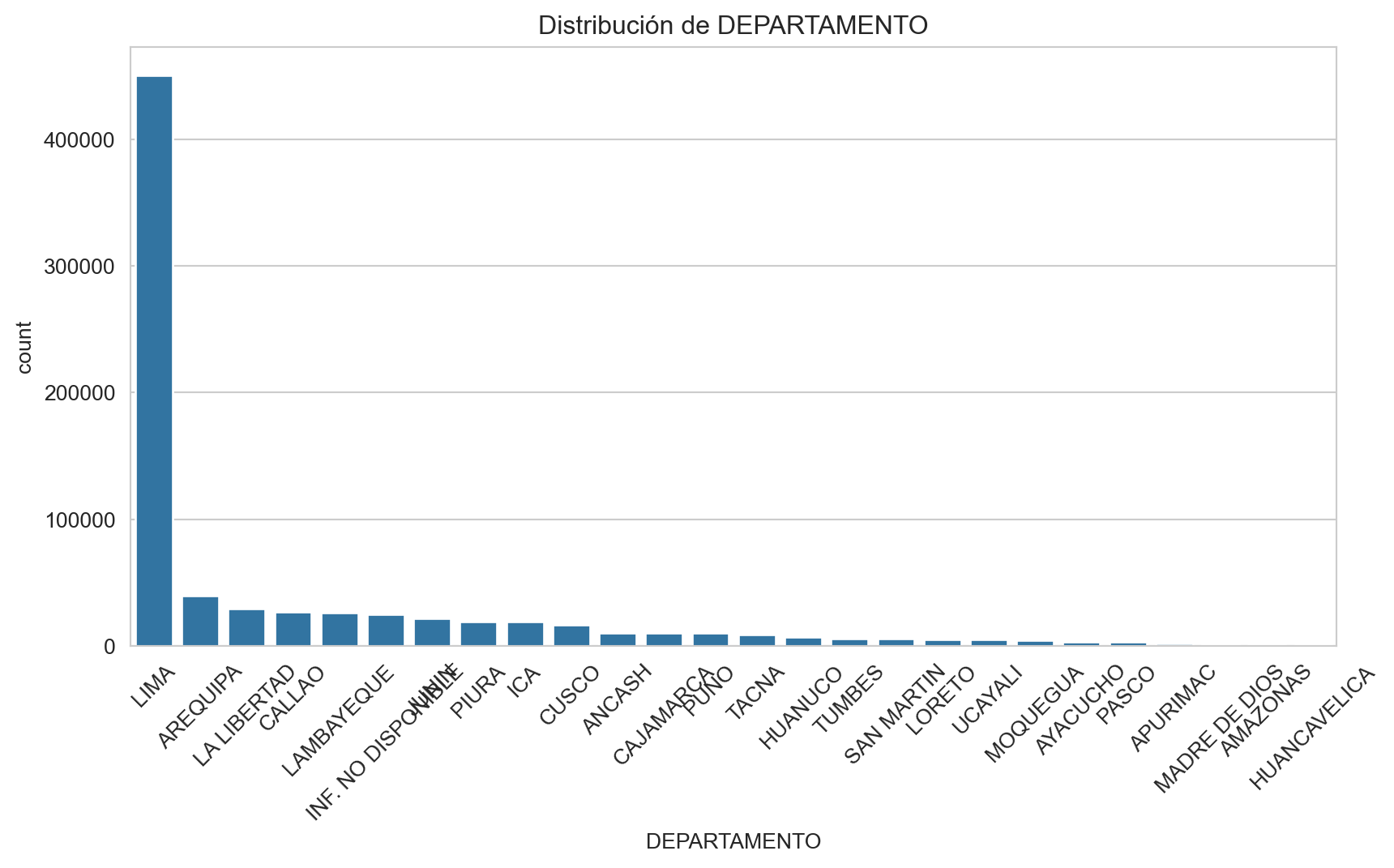
Análisis bivariado
Correlaciones para variables numéricas
numeric_cols = data_train.select_dtypes(include=['float64', 'int64']).columns
correlation_matrix = data_train[numeric_cols].corr()
# Visualizar la matriz de correlación con Seaborn
plt.figure(figsize=(15, 10))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title("Matriz de Correlación")
plt.show()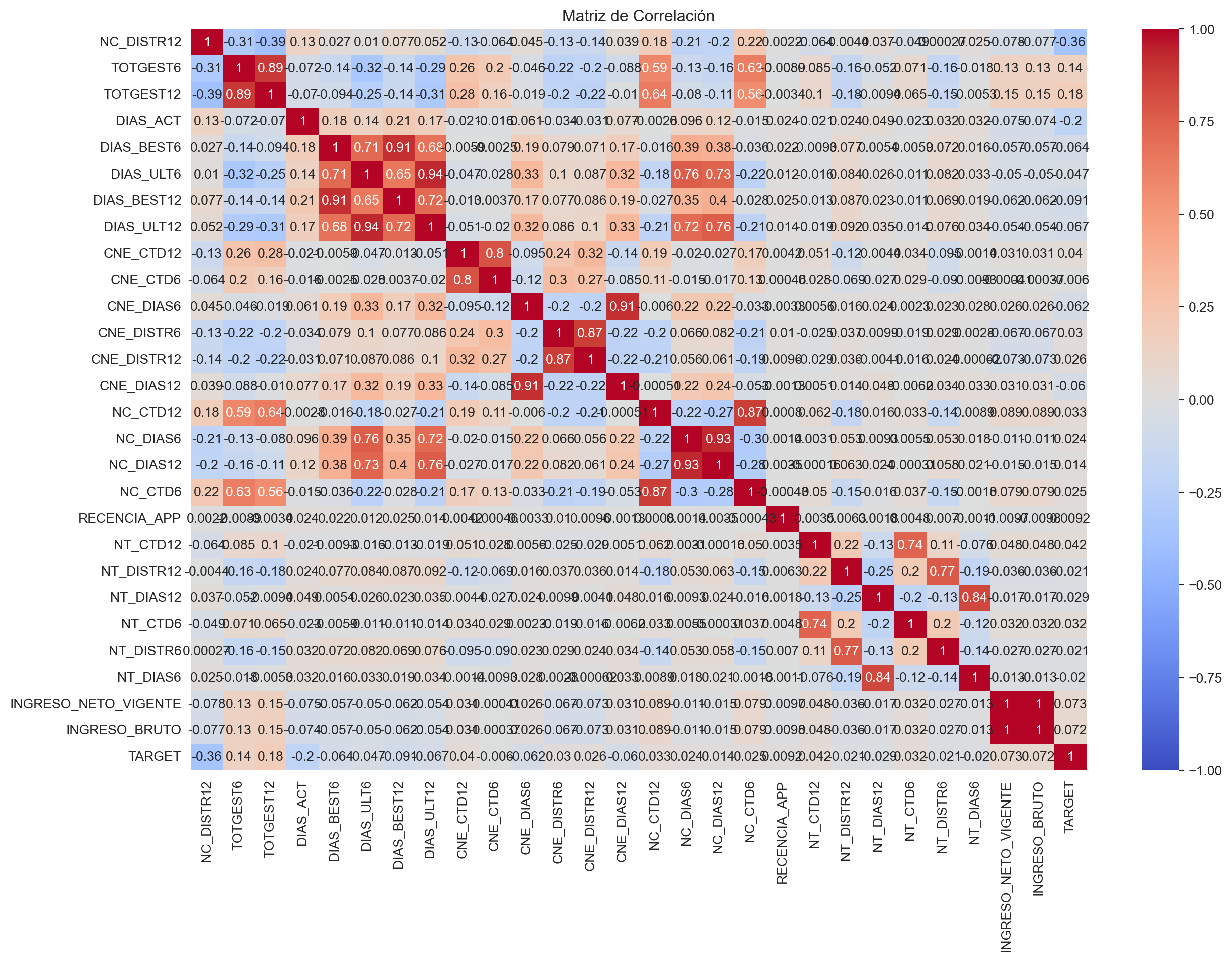
Los resultados de las correlaciones muestran que las variables DIAS_ACT, DIAS_BEST6, DIAS_BEST12, DIAS_ULT6, DIAS_ULT12, CNE_CTD6, CNE_CTD12, CNE_DIAS6, CNE_DIAS12, CNE_DISTR6, CNE_DISTR12, NC_CTD6, NC_CTD12, NC_DIAS6, NC_DIAS12, NC_DISTR12, TOTGEST6, TOTGEST12, INGRESO_NETO_VIGENTE, INGRESO_BRUTO tienen una correlación baja con la variable objetivo TARGET.
Por otro lado, las variables que presentan una alta correlación con la variable objetivo TARGET son NUMPRIORIZACION y SEGMENTO.
Análisis de la variable objetivo
# Frecuencia absoluta
frec_abs = data_train['TARGET'].value_counts()
# Frecuencia relativa (porcentual)
frec_rel = data_train['TARGET'].value_counts(normalize=True) * 100
# Consolidar ambas frecuencias en un solo DataFrame
desc_stats = pd.DataFrame({'Frecuencia Absoluta': frec_abs,
'Frecuencia Porcentual (%)': frec_rel})
print(desc_stats) Frecuencia Absoluta Frecuencia Porcentual (%)
TARGET
1 492388 65.011328
0 265000 34.988672# Gráfico de barras
plt.figure(figsize=(8, 6))
sns.countplot(data=data_train, x='TARGET')
plt.title("Distribución de la variable objetivo 'TARGET'")
plt.ylabel("Cantidad")
plt.xlabel("Valor de TARGET (0 = No Contacto Efectivo, 1 = Contacto Efectivo)")
plt.show()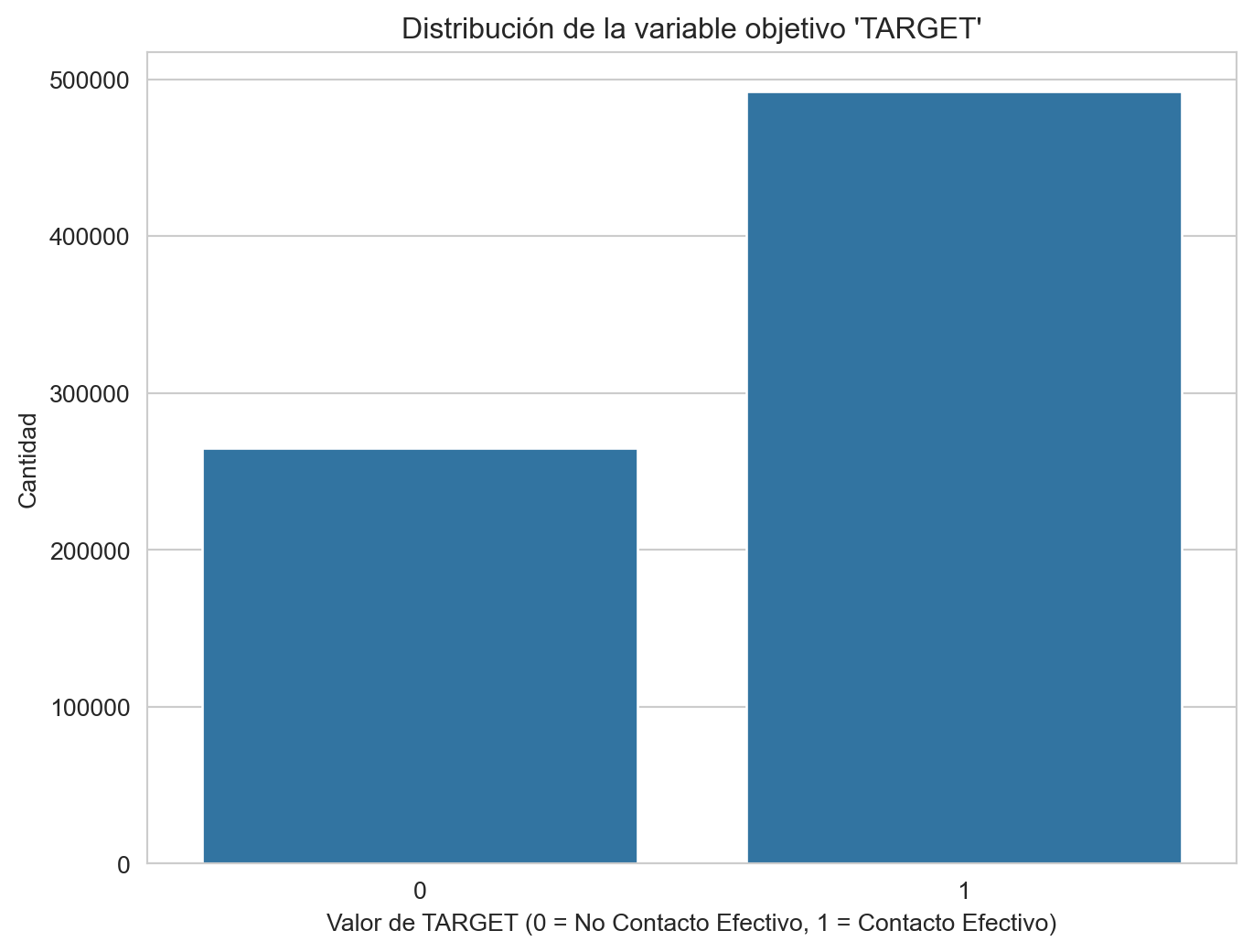
Mostramos la relación entre la variable objetivo y otras variables categóricas:
cat_vars = data_train.select_dtypes(include=['object', 'category']).columns.tolist()
# Si deseas excluir la variable objetivo de esta lista (en caso de que sea categórica)
if 'TARGET' in cat_vars:
cat_vars.remove('TARGET')# Configurar el tamaño de los gráficos
plt.figure(figsize=(15, 5 * len(cat_vars)))
for i, var in enumerate(cat_vars, 1):
plt.subplot(len(cat_vars), 1, i)
sns.countplot(data=data_train, x=var, hue='TARGET')
plt.title(f"Relación entre TARGET y {var}")
plt.ylabel("Cantidad")
plt.legend(title="TARGET", labels=["No Contacto Efectivo", "Contacto Efectivo"])
plt.tight_layout()
plt.show()
Preparación de los datos
Eliminando variable temporal
for data in data_train, data_test:
data.drop("FEC_LLAMADA", axis=1, inplace=True)Codificando variables categóricas
# Selecciona las columnas categóricas
cat_columns = data_train.select_dtypes(include=['category']).columns.tolist()# Aplicar get_dummies
data_train_dummies = pd.get_dummies(data_train[cat_columns])
# Unir los DataFrames
data_train = pd.concat([data_train, data_train_dummies], axis=1)
# Eliminar variables categóricas originales
data_train.drop(cat_columns, axis=1, inplace=True)# Aplicar get_dummies
data_test_dummies = pd.get_dummies(data_test[cat_columns])
# Unir los DataFrames
data_test = pd.concat([data_test, data_test_dummies], axis=1)
# Eliminar variables categóricas originales
data_test.drop(cat_columns, axis=1, inplace=True)Quitando variables no vistas en entrenamiento pero sí en el conjunto de prueba:
data_test.drop(['MONTH_12','PROVINCIA_JULCAN','PROVINCIA_SUCRE'], axis=1, inplace=True)Separación de la base de datos
X_train = data_train.drop("TARGET", axis=1)
y_train = data_train[["TARGET"]]
X_test = data_test.drop("TARGET", axis=1)
y_test = data_test[["TARGET"]]Guardando base de datos preparada para el modelado
X_train.to_pickle("../data/interm/X_train_preparada.pkl")
X_test.to_pickle("../data/interm/X_test_preparada.pkl")
y_train.to_pickle("../data/interm/y_train_preparada.pkl")
y_test.to_pickle("../data/interm/y_test_preparada.pkl")Selección de variables
Cargando bases de datos preparadas para el modelado:
import pandas as pd
X_train_preparada = pd.read_pickle('../data/interm/X_train_preparada.pkl')
X_test_preparada = pd.read_pickle('../data/interm/X_test_preparada.pkl')
y_train_preparada = pd.read_pickle('../data/interm/y_train_preparada.pkl')
y_test_preparada = pd.read_pickle('../data/interm/y_test_preparada.pkl')from sklearn.ensemble import RandomForestClassifier
# Entrenar el modelo de Random Forest
model = RandomForestClassifier(n_estimators=100, random_state=2024)
model.fit(X_train_preparada, y_train_preparada)
# Obtener la importancia de las características
importances = model.feature_importances_
# Crear un DataFrame con las características y sus importancias
feature_importances = pd.DataFrame({'feature': X_train_preparada.columns, 'importance': importances})
# Guardando características y sus importancias
feature_importances.to_pickle('../data/final/feature_importances.pkl')# Cargar características y sus importancias
feature_importances = pd.read_pickle('../data/final/feature_importances.pkl')
# Ordenar las características por importancia
feature_importances = feature_importances.sort_values(by='importance', ascending=False)
# Mostrar las características más importantes
print(feature_importances)
# Seleccionar las características más importantes (por ejemplo, las 2 más importantes)
selected_features = feature_importances['feature'].head(10).tolist()
print("Características seleccionadas:", selected_features) feature importance
3 DIAS_ACT 8.359303e-02
0 NC_DISTR12 7.774602e-02
25 INGRESO_NETO_VIGENTE 5.917369e-02
26 INGRESO_BRUTO 5.891626e-02
27 NUMPRIORIZACION_1 5.141687e-02
.. ... ...
173 PROVINCIA_LA UNION 4.428344e-07
202 PROVINCIA_PALLASCA 3.354169e-07
251 PROVINCIA_VICTOR FAJARDO 2.629123e-07
299 RANGO_INGRESOS_NULO 1.205713e-07
66 COD_SALA_TC 4.331061e-08
[315 rows x 2 columns]
Características seleccionadas: ['DIAS_ACT', 'NC_DISTR12', 'INGRESO_NETO_VIGENTE', 'INGRESO_BRUTO', 'NUMPRIORIZACION_1', 'DIAS_BEST12', 'TOTGEST12', 'DIAS_BEST6', 'NC_DIAS12', 'DIAS_ULT12']Manteniendo sólo variables relevantes:
X_train_preparada = X_train_preparada[selected_features]
X_test_preparada = X_test_preparada[selected_features]Guardando base de datos preparada con variables seleccionadas para el modelado:
X_train_preparada.to_pickle("../data/final/X_train.pkl")
X_test_preparada.to_pickle("../data/final/X_test.pkl")
y_train_preparada.to_pickle("../data/final/y_train.pkl")
y_test_preparada.to_pickle("../data/final/y_test.pkl")Preámbulo sobre la evaluación de modelos
Cargando bases de datos preparadas para el modelado:
import pandas as pd
X_train = pd.read_pickle('../data/final/X_train.pkl')
X_test = pd.read_pickle('../data/final/X_test.pkl')
y_train = pd.read_pickle('../data/final/y_train.pkl')
y_test = pd.read_pickle('../data/final/y_test.pkl')Criterios de evaluación
Las métricas a evaluar son:
- accuracy_score
- precision_score
- recall_score
- entropy
- ROC-AUC
Las métricas a evaluar las obtendremos con la siguiente función.
def get_metrics(y, y_pred, y_pred_proba):
from sklearn.metrics import accuracy_score, precision_score, recall_score, log_loss, roc_auc_score
accuracy = accuracy_score(y, y_pred)
precision = precision_score(y, y_pred)
recall = recall_score(y, y_pred)
entropy = log_loss(y, y_pred_proba)
roc_auc = roc_auc_score(y, y_pred_proba[:,1])
return {'accuracy': round(accuracy, 2), 'precision': round(precision, 2), 'recall': round(recall, 2), 'entropy': round(entropy, 2), 'roc-auc': round(roc_auc, 2)}Definiendo funciones sobre predicción
La siguiente función permite obtener predicciones.
def predict(model, X):
y_pred = model.predict(X)
return y_predLa siguiente función permite obtener probabilidades de las predicciones.
def predict_proba(model, X):
y_pred_proba = model.predict_proba(X)
return y_pred_probaModelado
Importando librerías:
import mlflow
import mlflow.sklearnConectando la sesión de MLflow a Databricks CE:
mlflow.set_tracking_uri("databricks")Regresión logística
print("_____ Experimento: Regresión logística _____")
exp = mlflow.set_experiment(experiment_name="/logisticRegression")
print(f'Nombre del experimento: {exp.name}')
print(f'ID del experimento: {exp.experiment_id}')def track_model(run_name, penalty, class_weight):
mlflow.start_run(run_name=run_name)
run = mlflow.active_run()
print(f'Nombre de la ejecución activa es: {run.info.run_name}')
print(f'ID de la ejecución activa es: {run.info.run_id}')
tags = {
"Modelo": "Regresión Logística",
}
mlflow.set_tags(tags)
# Entrenando el modelo:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(penalty=penalty, class_weight=class_weight)
model.fit(X_train, y_train)
mlflow.sklearn.log_model(model, "Regresión Logística")
params = {
'penalty': penalty,
'class_weight': class_weight
}
mlflow.log_params(params)
# Obteniendo predicciones:
y_train_pred = predict(model, X_train)
y_test_pred = predict(model, X_test)
# Obteniendo probabilidades de las predicciones:
y_train_pred_proba = predict_proba(model, X_train)
y_test_pred_proba = predict_proba(model, X_test)
# Obteniendo métricas:
run_metrics_train = get_metrics(y_train, y_train_pred, y_train_pred_proba)
run_metrics_test = get_metrics(y_test, y_test_pred, y_test_pred_proba)
print(run_metrics_train)
print(run_metrics_test)
# Rastreando métricas sólo del conjunto de prueba
for metric in run_metrics_test:
mlflow.log_metric(metric, run_metrics_test[metric])
mlflow.end_run()track_model(run_name="Base", penalty='l2', class_weight=None)
track_model(run_name="Base", penalty='l2', class_weight='balanced')Arbol de decisión
print("_____ Experimento: Arbol de decisión _____")
exp = mlflow.set_experiment(experiment_name="/treeDecision")
print(f'Nombre del experimento: {exp.name}')
print(f'ID del experimento: {exp.experiment_id}')def track_model(run_name, max_depth, splitter):
mlflow.start_run(run_name=run_name)
run = mlflow.active_run()
print(f'Nombre de la ejecución activa es: {run.info.run_name}')
print(f'ID de la ejecución activa es: {run.info.run_id}')
tags = {
"Modelo": "Arbol de decisión",
}
mlflow.set_tags(tags)
# Entrenando el modelo:
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=max_depth, splitter=splitter, random_state=2024)
model.fit(X_train, y_train)
mlflow.sklearn.log_model(model, "Arbol de decisión")
params = {
'max_depth': max_depth,
'splitter': splitter
}
mlflow.log_params(params)
# Obteniendo predicciones:
y_train_pred = predict(model, X_train)
y_test_pred = predict(model, X_test)
# Obteniendo probabilidades de las predicciones:
y_train_pred_proba = predict_proba(model, X_train)
y_test_pred_proba = predict_proba(model, X_test)
# Obteniendo métricas:
run_metrics_train = get_metrics(y_train, y_train_pred, y_train_pred_proba)
run_metrics_test = get_metrics(y_test, y_test_pred, y_test_pred_proba)
print(run_metrics_train)
print(run_metrics_test)
# Rastreando métricas sólo del conjunto de prueba
for metric in run_metrics_test:
mlflow.log_metric(metric, run_metrics_test[metric])
mlflow.end_run()track_model(run_name="max_depth=3, splitter='best'", max_depth=3, splitter='best')
track_model(run_name="max_depth=5, splitter='best'", max_depth=5, splitter='best')
track_model(run_name="max_depth=7, splitter='best'", max_depth=7, splitter='best')
track_model(run_name="max_depth=3, splitter='random'", max_depth=3, splitter='random')
track_model(run_name="max_depth=5, splitter='random'", max_depth=5, splitter='random')
track_model(run_name="max_depth=7, splitter='random'", max_depth=7, splitter='random')Red neuronal
print("_____ Experimento: Red neuronal _____")
exp = mlflow.set_experiment(experiment_name="/neuralNetwork")
print(f'Nombre del experimento: {exp.name}')
print(f'ID del experimento: {exp.experiment_id}')def track_model(run_name, hidden_layer_sizes):
mlflow.start_run(run_name=run_name)
run = mlflow.active_run()
print(f'Nombre de la ejecución activa es: {run.info.run_name}')
print(f'ID de la ejecución activa es: {run.info.run_id}')
tags = {
"Modelo": "Red neuronal",
}
mlflow.set_tags(tags)
# Entrenando el modelo:
from sklearn.neural_network import MLPClassifier
model = MLPClassifier(hidden_layer_sizes=hidden_layer_sizes, random_state=2024)
model.fit(X_train, y_train)
mlflow.sklearn.log_model(model, "Red neuronal")
params = {
'hidden_layer_sizes': hidden_layer_sizes,
}
mlflow.log_params(params)
# Obteniendo predicciones:
y_train_pred = predict(model, X_train)
y_test_pred = predict(model, X_test)
# Obteniendo probabilidades de las predicciones:
y_train_pred_proba = predict_proba(model, X_train)
y_test_pred_proba = predict_proba(model, X_test)
# Obteniendo métricas:
run_metrics_train = get_metrics(y_train, y_train_pred, y_train_pred_proba)
run_metrics_test = get_metrics(y_test, y_test_pred, y_test_pred_proba)
print(run_metrics_train)
print(run_metrics_test)
# Rastreando métricas sólo del conjunto de prueba
for metric in run_metrics_test:
mlflow.log_metric(metric, run_metrics_test[metric])
mlflow.end_run()track_model(run_name="hidden_layer_sizes=25", hidden_layer_sizes=25)
track_model(run_name="hidden_layer_sizes=50", hidden_layer_sizes=50)
track_model(run_name="hidden_layer_sizes=75", hidden_layer_sizes=75)
track_model(run_name="hidden_layer_sizes=100", hidden_layer_sizes=100)Random forest
print("_____ Experimento: Random forest _____")
exp = mlflow.set_experiment(experiment_name="/randomForest")
print(f'Nombre del experimento: {exp.name}')
print(f'ID del experimento: {exp.experiment_id}')def track_model(run_name, n_estimators, max_depth):
mlflow.start_run(run_name=run_name)
run = mlflow.active_run()
print(f'Nombre de la ejecución activa es: {run.info.run_name}')
print(f'ID de la ejecución activa es: {run.info.run_id}')
tags = {
"Modelo": "Random forest",
}
mlflow.set_tags(tags)
# Entrenando el modelo:
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth, random_state=2024)
model.fit(X_train, y_train)
mlflow.sklearn.log_model(model, "Random forest")
params = {
'n_estimators': n_estimators,
'max_depth': max_depth
}
mlflow.log_params(params)
# Obteniendo predicciones:
y_train_pred = predict(model, X_train)
y_test_pred = predict(model, X_test)
# Obteniendo probabilidades de las predicciones:
y_train_pred_proba = predict_proba(model, X_train)
y_test_pred_proba = predict_proba(model, X_test)
# Obteniendo métricas:
run_metrics_train = get_metrics(y_train, y_train_pred, y_train_pred_proba)
run_metrics_test = get_metrics(y_test, y_test_pred, y_test_pred_proba)
print(run_metrics_train)
print(run_metrics_test)
# Rastreando métricas sólo del conjunto de prueba
for metric in run_metrics_test:
mlflow.log_metric(metric, run_metrics_test[metric])
mlflow.end_run()track_model(run_name="n_estimators=25 & max_depth=5", n_estimators=25, max_depth=5)
track_model(run_name="n_estimators=25 & max_depth=10", n_estimators=50, max_depth=10)
track_model(run_name="n_estimators=25 & max_depth=5", n_estimators=25, max_depth=5)
track_model(run_name="n_estimators=25 & max_depth=10", n_estimators=50, max_depth=10)Eligiendo el mejor modelo
Se compara el rendimiento de los modelos en Databricks CE. En la figura Figura 1 se muestran todos los experimentos realizados. Estos cuatro experimentos contienen en total 16 modelos como se muestra en la figura Figura 2.
La figura Figura 3 muestra el rendimiento de estos modelos basados primero en ROC_AUC, segundo en recall y por último en precisión.
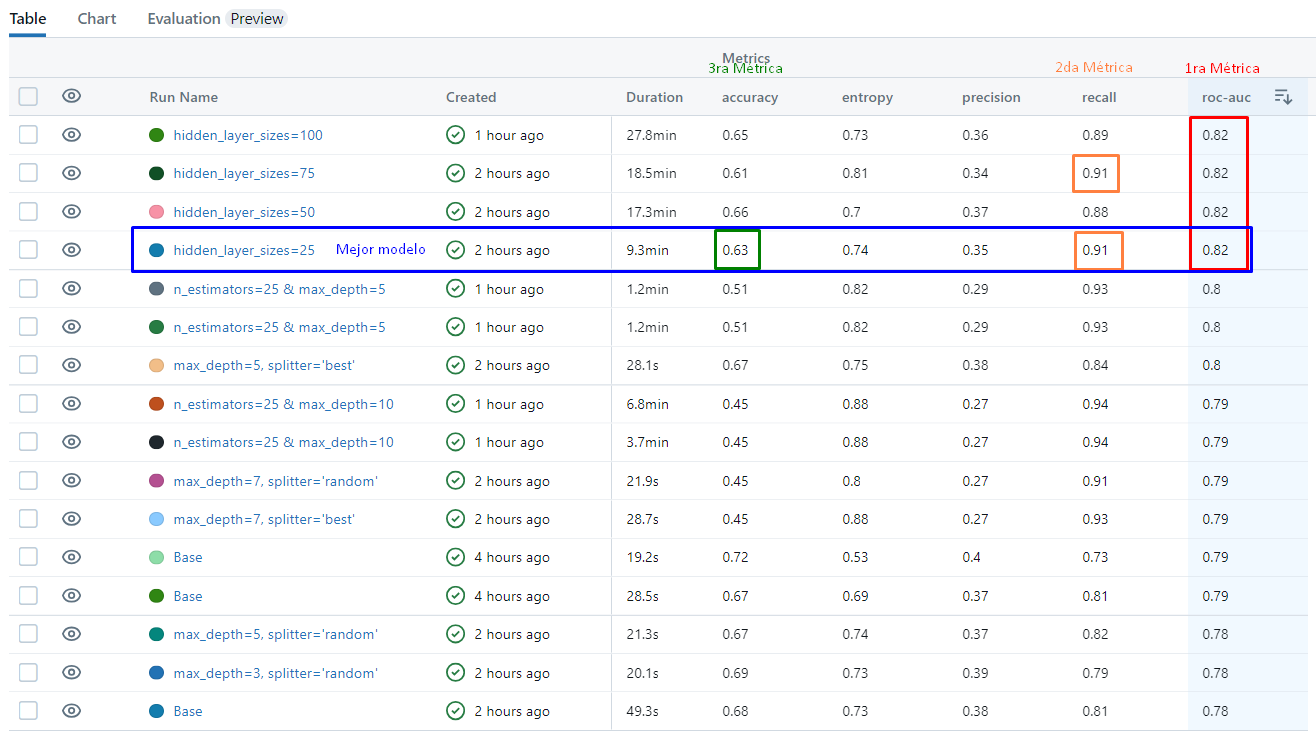
Los parámetros usados en los modelos se muestra en la figura Figura 4.
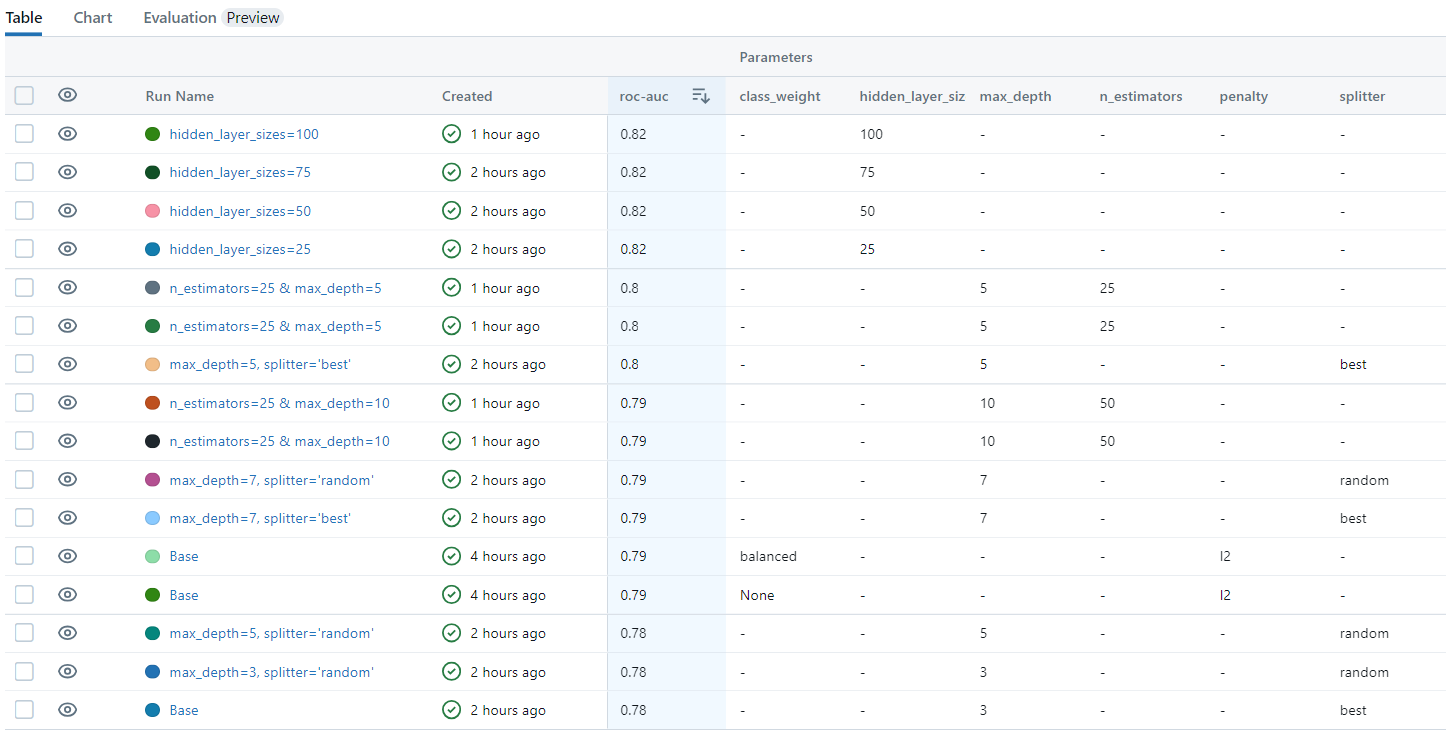
Conclusión
El mejor modelo resultó ser una red neuronal con un tamaño de capas ocultas igual a 50. Los mejores modelos fueron redes neuronales, seguido de random forest con n_estimators=25 y max_depth=5. Seguido de un árbol de decisión con max_depth=5 y splitter=‘best’. Por último, se encuentran el resto de modelos de árboles de decisión y regresión logística.